We've had 2 different 8.x clusters running for a number of years without issue however since upgrading to 8.17 (from 8.15.1) a couple of days ago we are seeing frequent heap allocation failures such as below:
#
# There is insufficient memory for the Java Runtime Environment to continue.
# Native memory allocation (malloc) failed to allocate 1048576 bytes. Error detail: AllocateHeap
# An error report file with more information is saved as:
# /usr/share/elasticsearch/hs_err_pid514.log
The behaviour of searching & indexing patterns is unchanged.
From the example above showing the failure to allocate memory, the recorded heap is not anywhere near the limit in the moments leading up to the crash: (the dip is when the pod restarted), which indicates lots of heap being allocated in a very narrow space of time?
e
For further curiosity, it is only our hot nodes (transform, data_hot & data_content are the roles it has that e.g. our warm nodes do not) that are seeing this issue, and also the OOM's are fairly distributed across these hot nodes; each hot node has OOM'd twice since upgrading 2 days ago; and each set of OOM's all seem to happen within a couple of hours of each other
These are the running args for the elastic process:
/opt/java/openjdk/bin/java -Des.networkaddress.cache.ttl=60 -Des.networkaddress.cache.negative.ttl=10 -XX:+AlwaysPreTouch -Xss1m -Djava.awt.headless=true -Dfile.encoding=UTF-8 -Djna.nosys=true -XX:-OmitStackTraceInFastThrow -Dio.netty.noUnsafe=true -Dio.netty.noKeySetOptimization=true -Dio.netty.recycler.maxCapacityPerThread=0 -Dlog4j.shutdownHookEnabled=false -Dlog4j2.disable.jmx=true -Dlog4j2.formatMsgNoLookups=true -Djava.locale.providers=SPI,COMPAT -Des.distribution.type=tar --enable-native-access=org.elasticsearch.nativeaccess,org.apache.lucene.core -XX:ReplayDataFile=logs/replay_pid%p.log -Djava.security.manager=allow -Des.cgroups.hierarchy.override=/ -Xms27136m -Xmx27136m -Xlog:async -Xlog:gc*,gc+ergo*=trace,gc+heap=debug,gc+age=trace,gc+metaspace=debug,gc+jni=debug,gc+ihop=debug,safepoint,stringdedup*=debug:file=/atcloud/gclogs/gc-elasticsearch-data-hot-3-2024_12_19-00_05.log:tags,time,level:filecount=3,filesize=10M -server -Xss1m -Xlog:gc+heap+coops=info -XshowSettings:vm -Djava.awt.headless=true -Dfile.encoding=UTF-8 -Djna.nosys=true -Dio.netty.noUnsafe=true -Dio.netty.noKeySetOptimization=true -Dio.netty.recycler.maxCapacityPerThread=0 -Dlog4j.shutdownHookEnabled=false -Dlog4j2.disable.jmx=true -XX:-OmitStackTraceInFastThrow -XX:+AlwaysPreTouch -XX:+UnlockExperimentalVMOptions -XX:+UseCondCardMark -XX:-UseSerialGC -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:GCPauseIntervalMillis=1000 -XX:InitiatingHeapOccupancyPercent=60 -XX:+ParallelRefProcEnabled -XX:+UseDynamicNumberOfGCThreads -XX:+PerfDisableSharedMem -XX:+AlwaysActAsServerClassMachine -XX:-ResizePLAB -Des.networkaddress.cache.ttl=30 -Des.networkaddress.cache.negative.ttl=0 -Des.allow_insecure_settings=true -XX:MaxDirectMemorySize=14227079168 -XX:G1ReservePercent=25 --module-path /usr/share/elasticsearch/lib --add-modules=jdk.net --add-modules=ALL-MODULE-PATH -m org.elasticsearch.server/org.elasticsearch.bootstrap.Elasticsearch
The Kubernetes pods themselves have 15 CPU with 53Gi memory (request, no explicit limit)
The main things I could see in the changelog notes between 8.15 & 8.17 was around the logsdb index type but I can confirm we have not created any indices using this type (other than any Elastic managed stuff like APM that may be using them), otherwise we don't use any datastreams.
Happy to grab any further information that could be useful, we have recorded metrics around plenty of index stats etc. but I've yet been able to make any correlation to what's happening when these OOM's occur (other than searching/indexing rates looking consistent)
Our other smaller cluster (2 hot nodes, 7 CPU, 25Gb memory, 12800m heap) is also displaying the exact same OOM's since uprading to 8.17, and again the heap looks very under utilized when the OOM happens (in this example ~22:30):
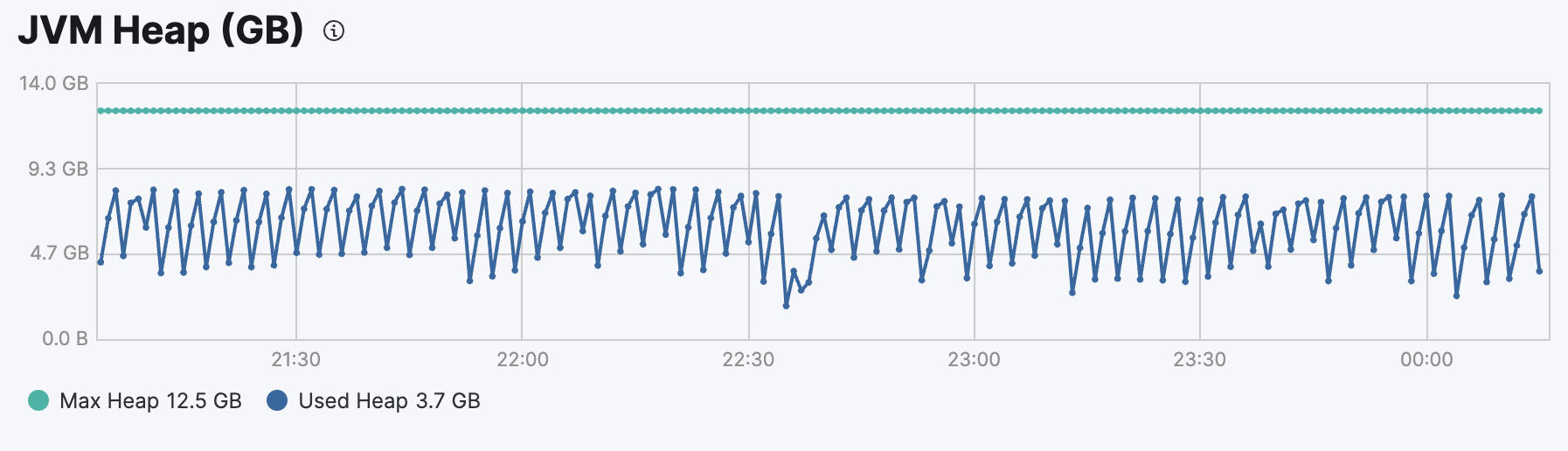
Edit: I'm now understanding that the memory allocation failure is for memory allocated outside the heap, though I'm still not sure what changes were in 8.16/8.17 that would change the memory profile of these hot nodes