Hi,
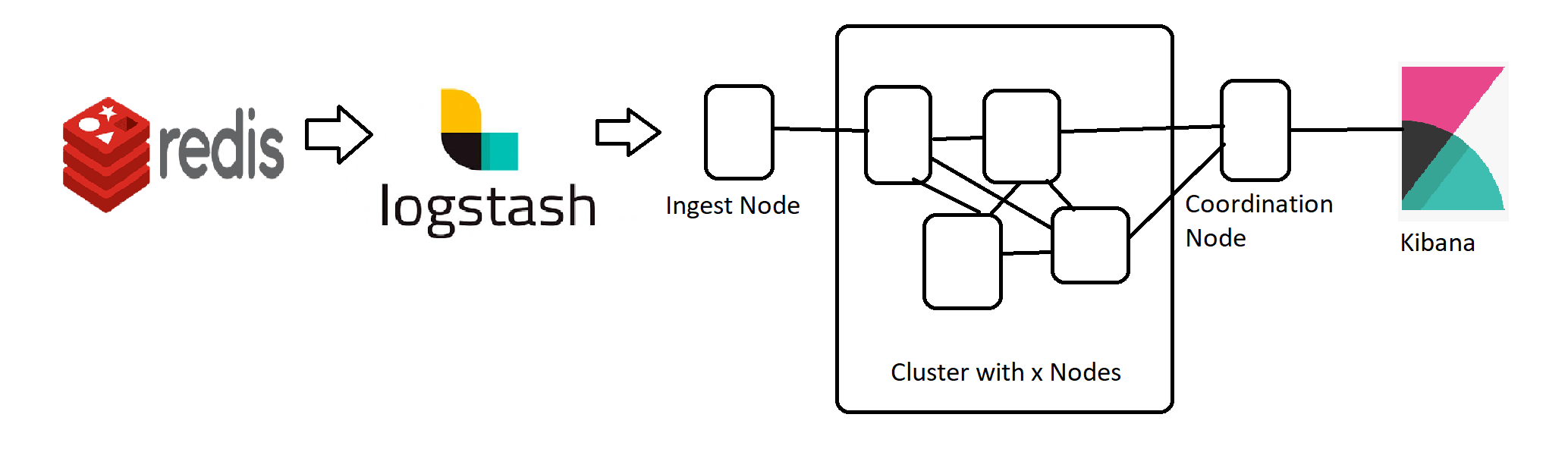
I have learned a lot about clusteres in the past 2 weeks but one thing which I dont get the hang of is how to talk to the cluster. What i mean is that I have a Redis Database and I would like to ingest data into a Hot-Warm cluster through Logstash. I know that a thing like an Ingest and Coordination Node exists but this would lead to single point of failures right?
How do I set up a reliable cluster with no single point of failures (Failover procedures)? Is it possible to talk to all Nodes at once and the nodes itself decide which node has to perform which task? Hope you understand what I am trying to say.
Thanks
Defalt
The default configuration has all nodes have all roles, and this is a great place to start. Just because you CAN have dedicated node types does not mean you SHOULD.
Around 5k-7k€. We think we would start with 3-5 Nodes and upgrade the cluster as we need more capacity.
Is it possible with logstash that it switches nodes if
One node is under heavy load
The node which its ingesting to goes down.
I know that Kibana has such capabilites with elasticsearch.hosts:
My new idea for the cluster would be that Kibana and logstash have connections to all nodes and than they decide which one should be used(Just like elasticsearch.hosts. Is that the right approach?
In all honesty, I wouldn't be too worried about SPOFs. If this is business critical and you cannot do without downtime, then the business needs to value it appropriately.
Just aim for a 3+ node cluster, across different data centres in the same geographic region. Use replicas, automatic backups, stay up to date with your packages. Use ILM + SLM if you can. Things like that will help while maintaining your budget.
We currently have 8 Snapshots over the course of 4 years. What is the best way to restore all that data and how should we approach this in the future? Currently we are just restoring the snapshots and creating new Indices for each. Each snapshot contains 5 Indices so in the end we will have 40 indices.
Yes, but the restored data is smaller than the original index because its incremental. So is it better to reindex them together into one big index or multiple smaller ones.
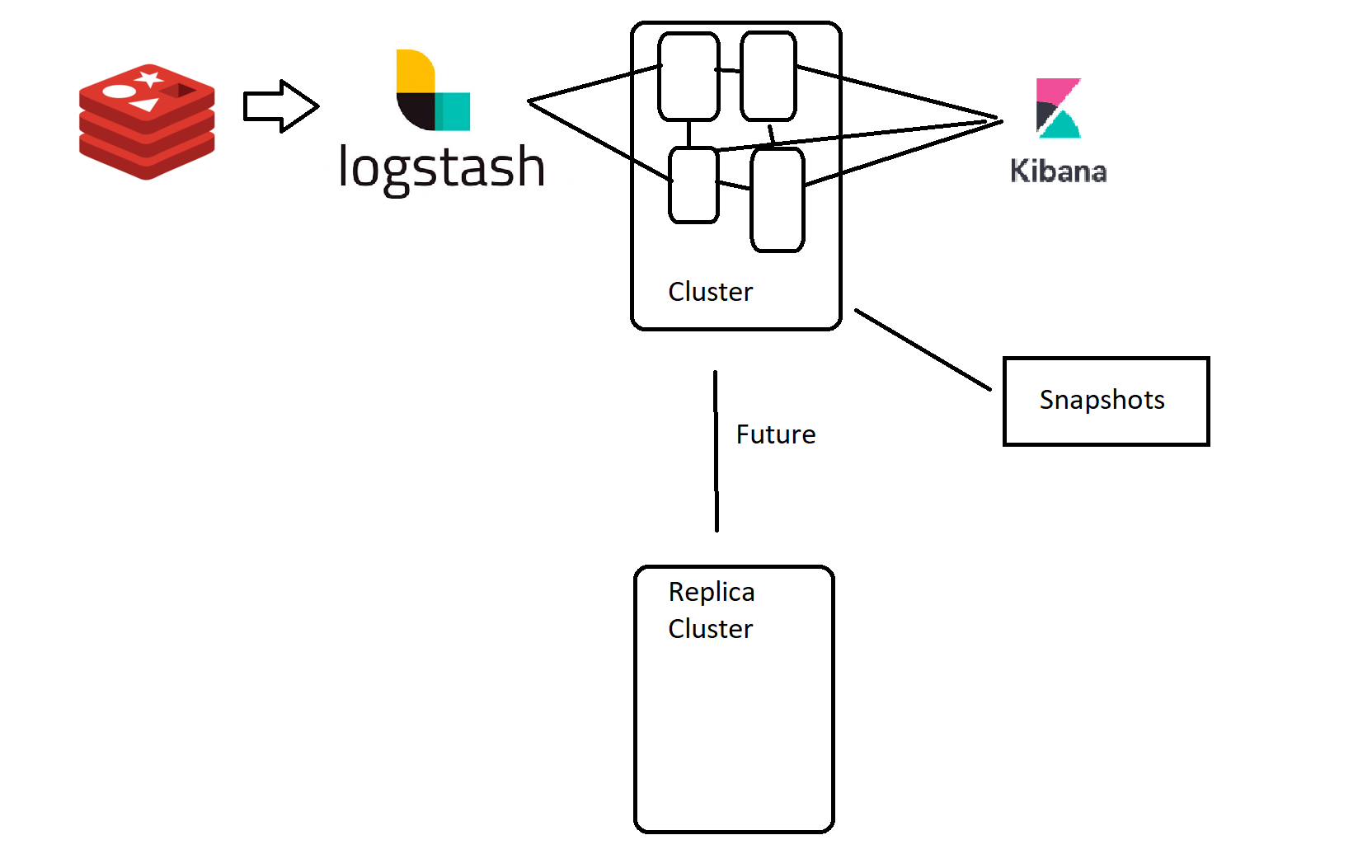
Reading all your answers this would be the setup with which i came up with. Is this a good approach?
A colleague raised the question if its possible to have Cluster A with online primary shards and indices and all the replicas are in the replica cluster B. Does this concept have any usecase?
Dear Mark, this is a very good point - what if you take a snapshot lets say every day from the Hot-node and delete all data which is older than 2 weeks. If you want to restore all data from an index (or at least 1 year or so) how can this be done since the last snapshot has not all data available right?
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.