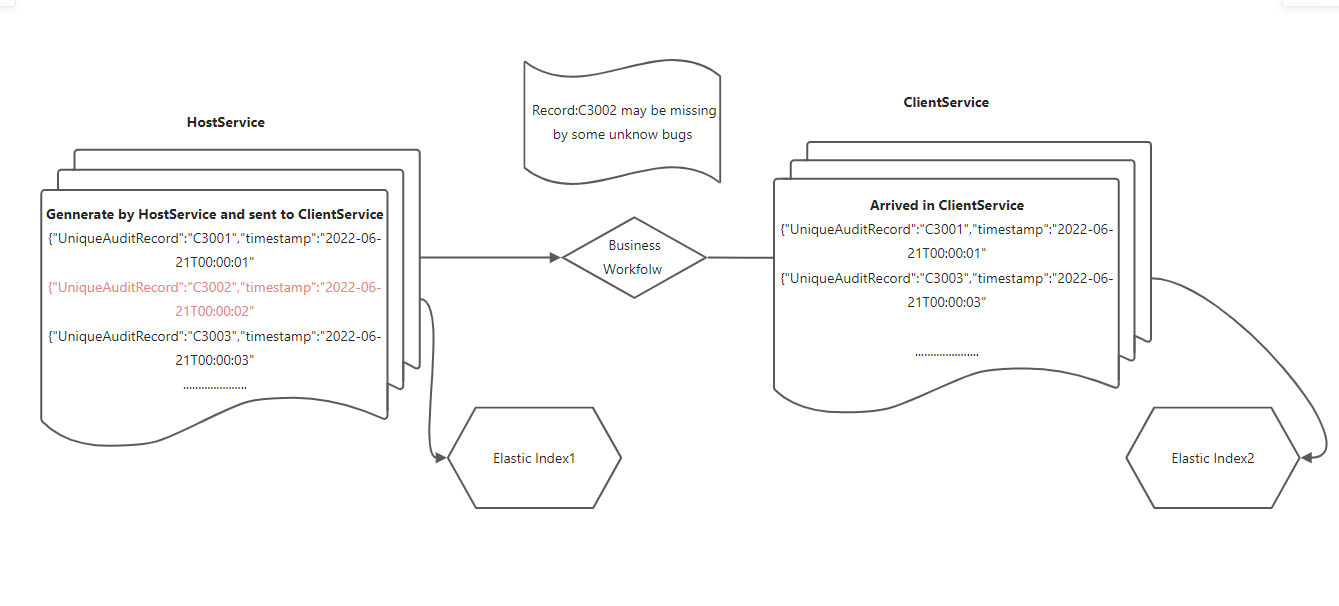
I need to use ES to realize an automatic function of detecting lost logs,Company don't want to write extra code
The method is as follows:
Through filebeat, log is continuously sent to two indexes from different source, one of which is generated when the business process is started, and the other is generated when the business process is completed,then set a alerting query in Kibana,while query return Hits it will trigger alerting action
mock data below is the log generated while process is started,
The data here is complete!
{“UniqueID”:“C001”,“timestamp”:“2022-06-01-T00:00:01”,"src":"start"}
{“UniqueID”:“C002”,“timestamp”:“2022-06-01-T00:00:02”,"src":"start"}
{“UniqueID”:“C003”,“timestamp”:“2022-06-01-T00:00:03”,"src":"start"}
{“UniqueID”:“C004”,“timestamp”:“2022-06-01-T00:00:04”,"src":"start"}
And data generated while process is end
There may be missing data here
{“UniqueID”:“C001”,“timestamp”:“2022-06-01-T00:00:01”,"src":"end"}
{“UniqueID”:“C003”,“timestamp”:“2022-06-01-T00:00:03”,"src":"end"}
Data format is above,Filed UniqueID is a key value ,timestamp means when this log was generated in system
we can see that if we compare 2 parts of them,there are no logs which UniqueID is C002 & C004 in “end index”
But there is a practical problem ,The log which UniqueID is C004 maybe still runing in system,
so we can't consider it as a missing one,In this case we can only care about the C002 one as a missing log
In other words ,I need to find the max timestamp value in “end index”,and the logs in “start index” which timestamp is below the max timestamp is the search range
In SQL SERVER ,I can put 2 parts of data into one table and query by the sql below
select UniqueID from dbo.kibanaLog GROUP BY UniqueID HAVING COUNT(*) = 1
and max(timestamp) <(select max(timestamp)from dbo.kibanaLog WHERE SRC='END' )
It will get correct records,but ES-SQL can not supprot complex sub-select
who can give me some ideas?
Thank you