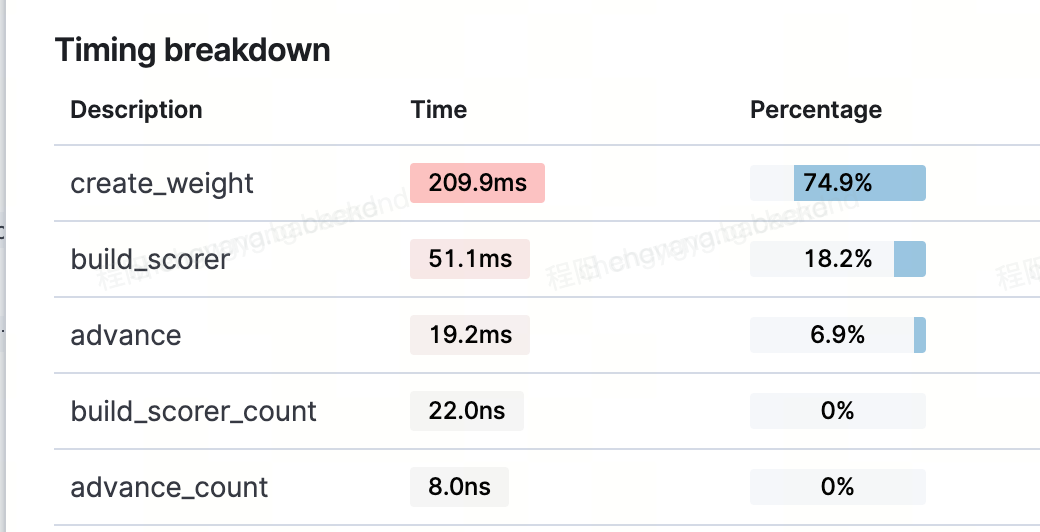
If you want someone to be able to help out or provide feedback you will need to provide a lot more details and context. I do not think anyone can help you based on what you have provided so far.
Please try to explain the problem in detail and provide the following:
Which version of Elasticsearch are you using?
What is your use case?
What does your dat, mappings and indexing/sharding strategy look like?
What does a query posing the problem look like?
What does a sample document look like?
What is the size and hardware specification of the cluster?