Hi,
I need to deploy scalable ELK stack (with further adding nodes), and I didn't find any complete tutorial for this - thats why I'm kindly asking you for help here.
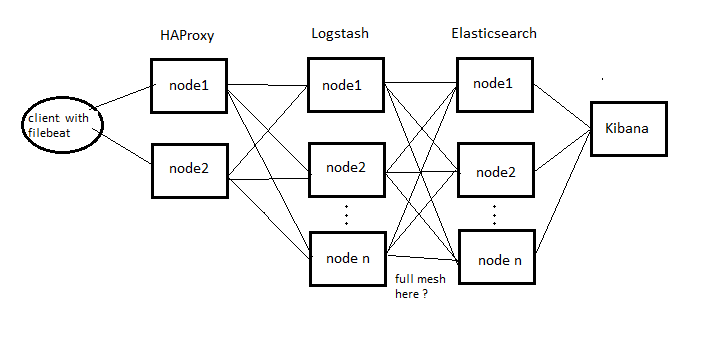
I saw some partial descriptions how to do that so I imagine that architecture of this environment could looks like on below picture. But maybe I'm wrong.. please take a look.
The goal is: build HA EL stack with possibility to scale (add nodes). Kibana on the end can be just one (without HA). I know already that there is possible for connect KIbana to many Elastics so lets leave it this thread.
Is my idea sensible ? is it possible at all ? if no please tell how to do this in other way. Best would be with link to some tutorial.
If it is possible then:
a) how to configure Logstashes to connect with every Elastics ?
b) is this full mesh (on the picture) necessary or not ?
c) the logs in Logstashes wouldn't be doubled while will be written from two sites (from 2 haproxys) ?
Yes, you can definitely deploy scalable ELK stack as ELK is designed to be scalable. But I believe all the beats can send to multiple Logstash at the same time, so there's no need for HAProxy in front of Logstash
However, for Logstash I don't think you would need that many instances. Two instances should be good enough to handle thousands of messages per second with some config changes from the default.
Hi, most of all many thanks for answer. However still I have doubts so please look on next questions..
[quote]
Yes, you can definitely deploy scalable ELK stack as ELK is designed to be scalable. But I believe all the beats can send to multiple Logstash at the same time, so there's no need for HAProxy in front of Logstash [/quote]
Ok, but in that situation where exactly is load balancing ? Because with HAProxy some part of connections would be directed to first Logstash and next part to the second. But here without HAProxy sample client will send doubled logs to both Logstahes so they both will be loaded same as if would be just one..
I'm not sure I understood that correctly.. About which mess we are talking ? Between LS and ES ? if so does full mesh (as I draw on picture) is necessary ?
Do you have some proof for that ? Some link to documentatation or another person's post ?
And last important question: when in this environment I should use some broker like Redis or RabbitMQ ?
Filebeat will do the load balancing. It will split the load among all the Logstash instances rather than send the same log to all Logstash instances .Otherwise, Elastic wouldn't allow specifying multiple Logstash instances in Filebeat config. If you are still in doubt, it's very easy to test, or some Elastic supporters like @warkolm can confirm this.
Yes, between LS and ES. Personally, I would configure LS to connect to at least 2 ES. About full mess, it will depend on how many ES instance you will have. If I have 10 ES, perhaps I would let LS1 > ES 1 through 2, and LS2 > 6 through 10.
HAProxy is quite effective for distributing short-lived connections, but Filebeat maintains long-running connections. The only time HAProxy will do any good is when new connections are being set up, but that'll happen quite rarely.
[quote]
Yes, between LS and ES. Personally, I would configure LS to connect to at least 2 ES. About full mess, it will depend on how many ES instance you will have. If I have 10 ES, perhaps I would let LS1 > ES 1 through 2, and LS2 > 6 through 10. [/quote]
Sorry but I don't get it. Or maybe other question: what should be principle of connect many Elasticsearches to many Logstash to everything work good. Though I can think of different configurations. e.g 4 LS and 8ES or , 2LS and 14ES and so on.
Moreover you didn't reply for this important question:
When in this environment I should use some broker like Redis or RabbitMQ ?
First of all, what is the scale of your environment? Unless you are receiving TB of data everyday, there's no need to worry about such scaling for now. With 2 Logstash instances and 4 ES instances, I can index hundreds of GB per day or nearly 10,000 events per second.
When you connect LS to at least 2 ES, LS will distribute the events in round robin to all ES, no duplicated events. I think the issue may arise is that when you connect one LS to like 15 ES, the TCP connections MAY cause some performance issues on the LS host. Unfortunately, I'm not lucky enough to have an environment that requires that many ES instances in a cluster. Instead, I run 4 separate clusters. I guess @magnusbaeck can tell you whether you should do 1 LS instance to 10+ ES instances or not.
To be specific, I think with Filebeat you don't need a broker because if LS is down, Filebeat will just stop reading files and wait for LS to be back and start to send events to LS again.
On the other hand, Metricbeat captures and sends events to LS with some small buffer in memory, but without any local cache/temp storage. Therefore, if your Logstash is down, you will lose events from Metricbeats after certain period. I belieave Metricbeat will stop collecting events if it cannot connect to Logstash.
[quote]
First of all, what is the scale of your environment? Unless you are receiving TB of data everyday, there's no need to worry about such scaling for now. With 2 Logstash instances and 4 ES instances, I can index hundreds of GB per day or nearly 10,000 events per second. [/quote]
We have big environment. We'll have to handle about 100k per second, 10-20GB logs per day or even more! From that reason I'm thinking seriously about broker too. So first I would like to start with following architecture:
In this case I know that I should connect every Logstash to every Elasticsearch (roundrobin). But I don't know how to connect 2Redises to 2Logstashes. Also both to both ? won't be doubled logs ?
Regarding that official documentatoin: https://www.elastic.co/guide/en/logstash/current/deploying-and-scaling.html. Why in this fucking documentation (sorry but I'm getting nervous) there isn't any one word HOW EXACTLY connect partial elemnts like Logstash, Redis, Elaasticsearch, filebeat and other to each other ?! in which architecture ? parallel or roundrobin or series or how ?? This is the main reason I'm writing this post here. Fuck...
Last doubt which I have is whether to use Redis or RabbitMQ.
Why in this fucking documentation (sorry but I'm getting nervous) there isn't any one word HOW EXACTLY connect partial elemnts like Logstash, Redis, Elaasticsearch, filebeat and other to each other ?!
Because there isn't a single answer that fits everyone.
Your volume numbers do not really add up. An average of 100k events per second is 8.64 billion events per day. If the total data volume is 20GB, that is 2.5 bytes per event. What volume are you sizing for?
There are usually two main reasons for introducing a message broker. The first is to allow buffering in case you have inputs that do not handle back-pressure well. Logstash 5.1 has support for persistent queueing on disk which allows it to queue a configurable amount of data on disk, so you may be able to get away without a message queue for this reason. The second is to decouple collection from processing or indexing, which is very useful when you have a large number of Logstash indexers and want to efficiently and evenly distribute load across them
If you plan on starting out with 4 Elasticsearch nodes and 2 Logstash instances, and all your inputs come from Filebeat (which can generally handle back-pressure well) I suspect you may not need to introduce any message queue at this point.
With all the respect but in documentation there should be described all the variants of type of connections between applications and how to connect them to each other in case of scaling - this is basic thing though.
What volume are you sizing for? It is reasonably easy to change architecture of the ingest pipeline as your volumes increase, and the simple architecture without any message queue can scale to quite large volumes, so if you only initially will have a couple of Logstash instances I would start with that.
Logstash applies back-pressure automatically, meaning that if it can not output events fast enough and there is no more internal storage available, it will simply stop reading from inputs until processing can start again.
Well we plan to have 20GB of logs daily, more we don't know. Maybe you're right, we will start from 2 LS and 4ES.
This isn't explanation or proof for superiority of that solution because Redis in that situation will write logs to buffer (AFAIK) so we can say would be better (than rejecting logs by LS)
This isn't explanation or proof for superiority of that solution because Redis in that situation will write logs to buffer (AFAIK) so we can say would be better (than rejecting logs by LS)
Yes, but adding more infrastructure like Redis is a risk in itself.
As I said, there is no ideal solution that fits everyone. No matter what you choose there will be drawbacks. You always need to evaluate what works for you and which drawbacks are acceptable to you.
As the responses to your original question indicate, there is not a unique best design for all ELK stack instances.
My recommendation is to setup a cluster, watch as many metrics as you can and play with it.
If you have the available resources, I would recommend standing up a "standard" ELK stack with filebeat => logstash => ES cluster. Once this ELK stack is in place, play with it. Collect metrics on your throughput on the logstash instances, keep an eye on index rate on ES nodes given different query loads and number of nodes available. Turn services off and on to see what happens, add new nodes to your ES cluster and see the impact during rebalancing. There are some many things in addition to what I mentioned that you can play with. Once you have played and explored a basic ELK stack, decide for yourself what you need to do (ha proxy, queues,...) to make it work in your given scenario.
Note: Leave any of your old logging systems in place during this testing phase so you can comfortably make changes without losing any important logs.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.