Hi @Andrea_Spacca.
I didn't understand what needs to be done in this step, can you help me?
I configured my sarconfig.yaml like this:
- type: "cloudwatch-logs"
id: "arn:aws:logs:us-east-1:*******:log-group:/aws/lambda/******-dev-simulation-range"
outputs:
- type: "elasticsearch"
args:
# either elasticsearch_url or cloud_id, elasticsearch_url takes precedence
#elasticsearch_url: "http(s)://domain.tld:port"
cloud_id: "AWS_C**************************************DFkOTY3Yw=="
# either api_key or username/password, api_key takes precedence
api_key: "**********************************"
#username: "username"
#password: "password"
es_datastream_name: "test-no-range"
batch_max_actions: 500
batch_max_bytes: 10485760
I provided the permissions for the lambda to access cloudwatch:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"logs:ListTagsLogGroup",
"logs:DescribeLogGroups",
"logs:DescribeLogStreams",
"logs:DescribeSubscriptionFilters",
"logs:StartQuery",
"logs:GetLogEvents",
"logs:DescribeMetricFilters",
"logs:FilterLogEvents",
"logs:GetLogGroupFields"
],
"Resource": [
"arn:aws:logs:us-east-1:******:log-group:/aws/lambda/dev-simulation-range",
"arn:aws:logs:us-east-1:******:log-group:/aws/lambda/dev-simulation-range:*"
]
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": [
"logs:DescribeQueries",
"logs:DescribeExportTasks",
"logs:GetLogRecord",
"logs:GetQueryResults",
"logs:StopQuery",
"logs:TestMetricFilter",
"logs:DescribeQueryDefinitions",
"logs:DescribeResourcePolicies",
"logs:GetLogDelivery",
"logs:DescribeDestinations",
"logs:ListLogDeliveries"
],
"Resource": "*"
}
]
}
Trigger added:
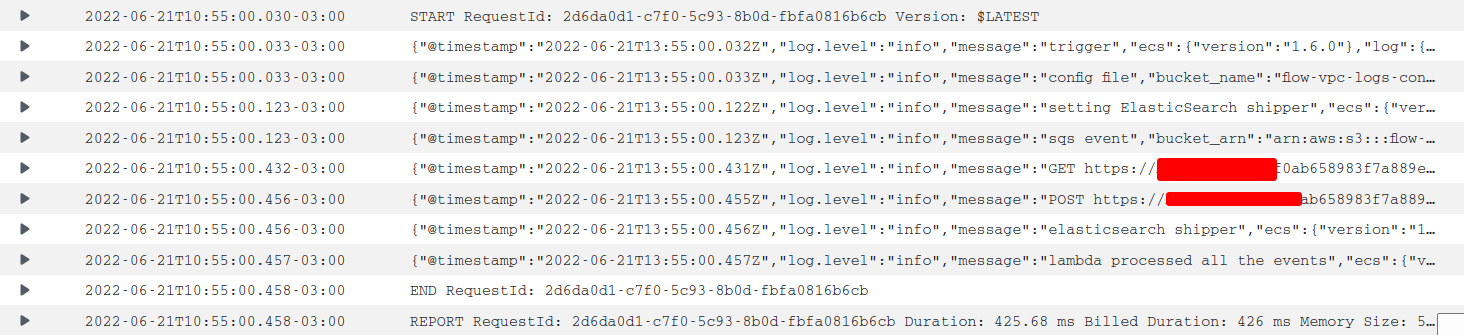
I don't see anything different in the lambda log:
No errors:
I take the opportunity to ask if the functionbeat works for me, why should I switch to sar? Sar is very complex to configure. With SAR metrics like: Lambda Top Invoked Functions [Metrics AWS
work? Because with functionbeat no, I have to do everything manually and I don't even know if I can have this level of data, since functionbeat only retrieves logs, but it seems that sar also only retrieves logs. Help me, documentation is very complex for newbies