Hello,
I am curious if anybody faced the issue I have
I have 5 documents with the following fields and values in table view:
+++++++++++++++++++++++++++++++++
| src_ch | tgt_ch | extra_field |
+++++++++++++++++++++++++++++++++
| a | b | - |
| a | b | - |
| b | a | - |
| b | a | - |
| - | - | blabla |
+++++++++++++++++++++++++++++++++
My goal is:
- Combine values from both "src_ch" and "tgt_ch" fields
- Get a list with unique values
- Calculate a number of unique values
- Be able to display results in a dashboard
So, the expected result is getting these values in the dashboard:
result: [a, b]
count: 2
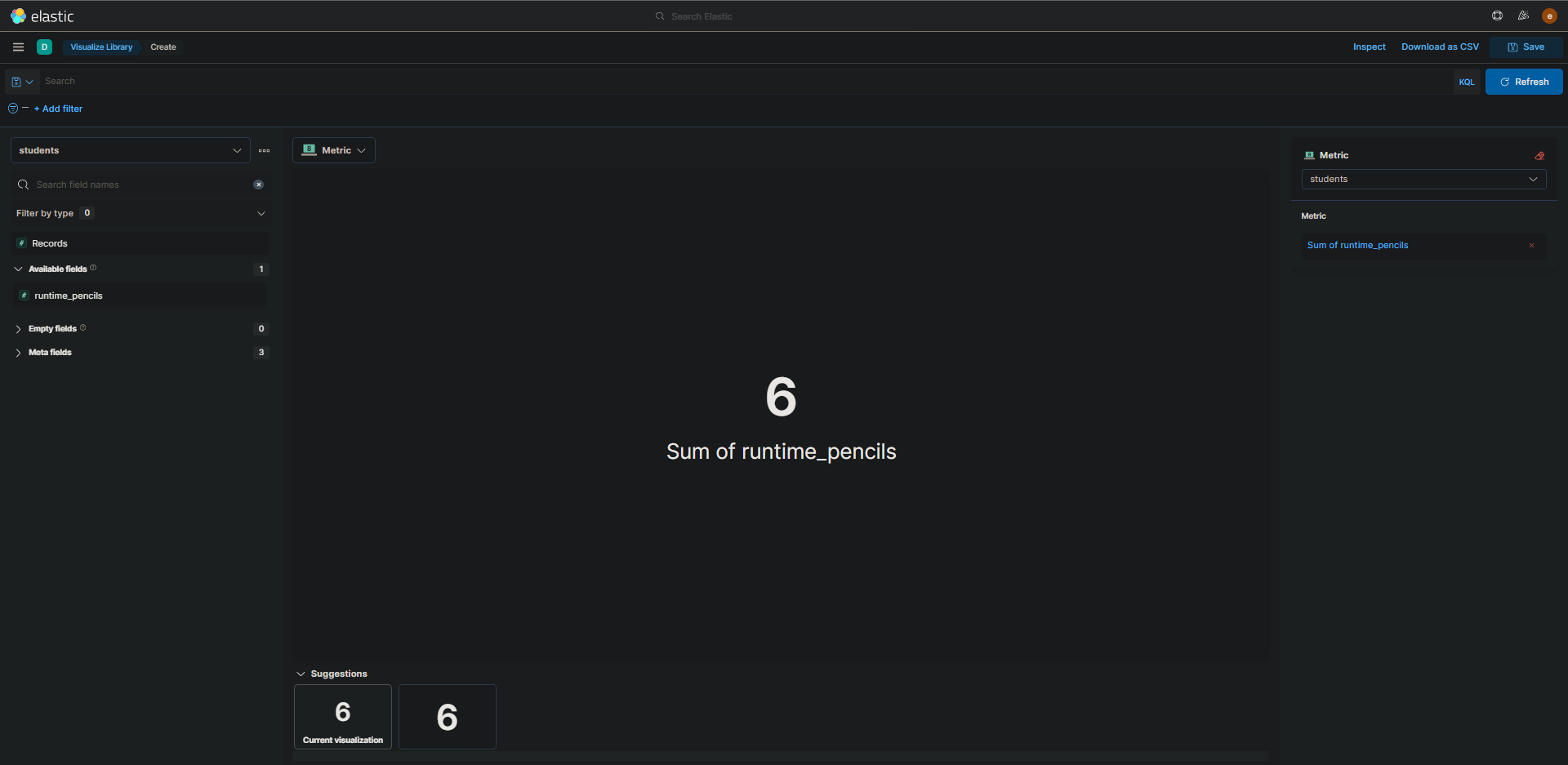
1.Initially I tried to build it via Visualize Library but failed to do it
2.Then I tried to get it at least via Search API request:
DELETE /my-index-000001/
POST /my-index-000001/_bulk?refresh
{"index":{}}
{"src_ch" : "a", "tgt_ch" : "a", "extra_field": "blabla"}
{"index":{}}
{"src_ch" : "a", "tgt_ch" : "b", "extra_field": "blabla"}
{"index":{}}
{"src_ch" : "b", "tgt_ch" : "a", "extra_field": "blabla"}
{"index":{}}
{"src_ch" : "b", "tgt_ch" : "b", "extra_field": "blabla"}
{"index":{}}
{"extra_field": "blabla"}
GET my-index-000001/_search
{
"query": {
"bool": {
"must": [
{
"exists": {
"field": "src_ch.keyword"
}
},
{
"exists": {
"field": "tgt_ch.keyword"
}
}
]
}
},
"_source": [
"src_ch",
"tgt_ch"
],
"from" : 0,
"size" : 0,
"aggs": {
"src_channels": {
"terms": {
"field": "src_ch.keyword"
}
},
"tgt_channels": {
"terms": {
"field": "tgt_ch.keyword"
}
}
}
}
and I almost got what I was looking for:
{
<...>
"aggregations" : {
"src_channels" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a",
"doc_count" : 2
},
{
"key" : "b",
"doc_count" : 2
}
]
},
"tgt_channels" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a",
"doc_count" : 2
},
{
"key" : "b",
"doc_count" : 2
}
]
}
}
}
but still no
3.Finally, I took a look at runtime fields but noticed that it requires having all data in one document while my data was distributed among 5 different docs
I changed the initial data structure to the nested one:
DELETE my-index-000001
PUT my-index-000001
{
"mappings": {
"properties": {
"docs": {
"type": "nested"
}
}
}
}
PUT my-index-000001/_doc/1
{
"docs": [
{ "src_ch" : "a", "tgt_ch" : "a", "extra_field": "blabla"},
{ "src_ch" : "a", "tgt_ch" : "b", "extra_field": "blabla" },
{ "src_ch" : "b", "tgt_ch" : "a", "extra_field": "blabla"},
{ "src_ch" : "b", "tgt_ch" : "b", "extra_field": "blabla"},
{"extra_field": "blabla"}
]
}
After this, I was able to achieve the required count value by using the following script for the runtime field:
def channels = [];
String element;
if (params['_source']['docs'] != null) {
if (params['_source']['docs'].size() != 0) {
for (def i = 0; i < params['_source']['docs'].length; i++) {
element = params['_source']['docs'][i]['src_ch'];
if ((element != null) && (!channels.contains(element))) {
channels.add(element)
}
element = params['_source']['docs'][i]['dst_ch'];
if ((element != null) && (!channels.contains(element))) {
channels.add(element)
}
}
}
}
emit(channels.length)
however, I failed to get a list the same way:
def channels = [];
String element;
if (params['_source']['docs'] != null) {
if (params['_source']['docs'].size() != 0) {
for (def i = 0; i < params['_source']['docs'].length; i++) {
element = params['_source']['docs'][i]['src_ch'];
if ((element != null) && (!channels.contains(element))) {
channels.add(element)
}
element = params['_source']['docs'][i]['dst_ch'];
if ((element != null) && (!channels.contains(element))) {
channels.add(element)
}
}
}
}
emit(channels)
due to the following error:
cannot implicitly cast def [java.util.ArrayList] to java.lang.String
I did not find how to explicitly specify in Runtime field settings that I expect that a list is returned but scripted fields helped to workaround the issue here this way:
def channels = [];
String element;
if (params['_source']['docs'] != null) {
if (params['_source']['docs'].size() != 0) {
for (def i = 0; i < params['_source']['docs'].length; i++) {
element = params['_source']['docs'][i]['src_ch'];
if ((element != null) && (!channels.contains(element))) {
channels.add(element)
}
element = params['_source']['docs'][i]['dst_ch'];
if ((element != null) && (!channels.contains(element))) {
channels.add(element)
}
}
}
}
return channels
So, briefly, my questions are the next:
- Am I correct that we cannot perform any actions with fields located in 2 different documents?
- Am I correct that having all data in one document there is no way to join values from two different fields except by creating scripted or/and runtime fields?
- Am I correct that runtime and scripted fields will be consuming a lot of memory when a number of docs will be significant? Do we have some examples of how bad everything may be?
- Is there the correct way to resolve my initial problem?
Thank you!