I'm trying to find some response here, since I think I exhausted all my solutions on that problem.
I'm also totally new with this subject.
I am working on an old ELK (5.5), hosted on a docker in a dedicated VM hosted on mutualised server.
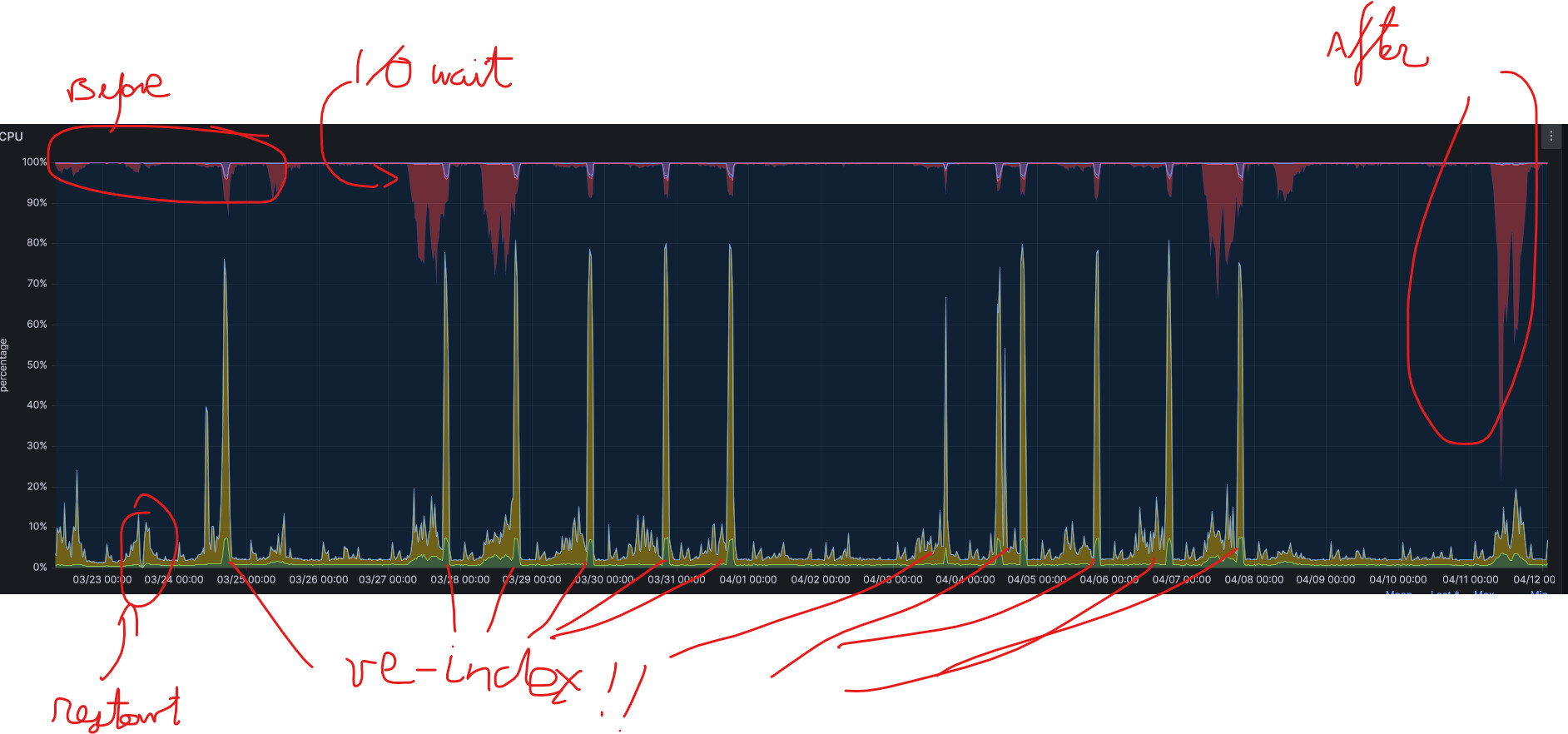
A list of actions had been made on it that had the consequence to dramatically increase the I/O Wait.
The VM has been put on a different disk, better faster and so on..
It has been restarted
Since it didn't worked properly, they restarted also the docker inside
During two weeks, a colleague made each day a reindexing on the whole ELK
-> what you can see during this period is that sometimes the I/O wait increases and some times it gets back to its old values.
As you can see on the stats on the attached image, sometimes the I/O wait increases and sometimes it gets back to normal during that period.
And now the I/O wait has increased so dramatically that the ELK slows down so much that some times the whole internet site is freezing.
We have 5 nodes on the cluster, the swap seems to be off and there is not much to read on the ealsticsearch.yml
So far, we tried force-merge and reindexing+forcemerge.. that seems to have increased the problem
May anyone experienced something similar and may have an idea about the causes and the solutions?
Hello,
i have some more information.
Apparently, those redindexing were coupled with force merge.
So apparently we have one very big segment and few very little, and that is what makes this important i/o wait
I'm surprised the bot hasn't come by here yet, but Elasticsearch 5.x is far past End of Life and you should really look into upgrading as a matter of urgency. You will not find many people around here with 5.x experience, or those who have it probably haven't used it in a long time.
(I do not have any 5.x experience, so take what I'm about to say with a grain of salt)
Any sort of I/O wait means that the server is waiting on disks for work, this indicates that Elasticsearch is trying to do more work than the disks can keep up with. With this piece of information in mind there are a few things to point out:
Both re-index and force-merge are I/O intensive functions. Seeing I/O utilization spike during these is to be expected.
Whether you see I/O wait increase goes back to the disks being the limiting factor here.
Restarting an Elasticsearch node can be an I/O intensive function. Elasticsearch needs to do various things on startup that involve reading data.
I think this has been improved in recent versions (again, extremely important to upgrade)
Some additional things:
the swap seems to be off
"Seems to be off", and "actually being off" are 2 different things, I'd confirm that swap is actually off.
The VM has been put on a different disk, better faster and so on.
What does this mean?
Is this local storage, or storage over some sort of network (SAN, NAS, etc...)?
What type of storage (spinning disk (HDD), SATA SSD, NVMe SSD, etc...)?
Can you provide more details?
It seems like you're running on Linux, what does iostat look like, what is the server waiting on?
How much data are we dealing with in this cluster?
Overall, just from looking at this, it seems like your disks/storage are not able to keep up with the demands of Elasticsearch. (Again, there are probably improvements in newer versions and you should really be upgrading, but I'm not 100% sure they'll fix your problem.)
We couldn't change version because the application is a very old legacy still on Hibernates 5 and apparently it was to expensive to change (Im in charge but alone and there only since March, when the problem actually appeared).
The Swap IS of, I could see it in the docker properties
The Virtual Machine is now on SSD (don't know all the details) and he storage is not local, but SAN
We are dealing with files, something like 4billion, each of it has several information indexed in the ELK. It is continuously rewritten and read, day and night. It has simultaneously several massive import and updates through a BUS.
The nodes have 200Gb each and are using 50Gb for the storage
Since last time, we tried some other things :
Deleting and recreating the index with reindexation, it did nothing
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.