Hello
I'm trying to understand something in the logic of Elasticsearch.
Here is my setup :
Graylog 4.2 cluster for ingesting logs
Connected to an ES 7.10 cluster
The Graylog cluster knows the ES Cluster by the Master nodes who are set in the Graylog's config files (as "discovery.seed_hosts" for thoses who knows Graylog).
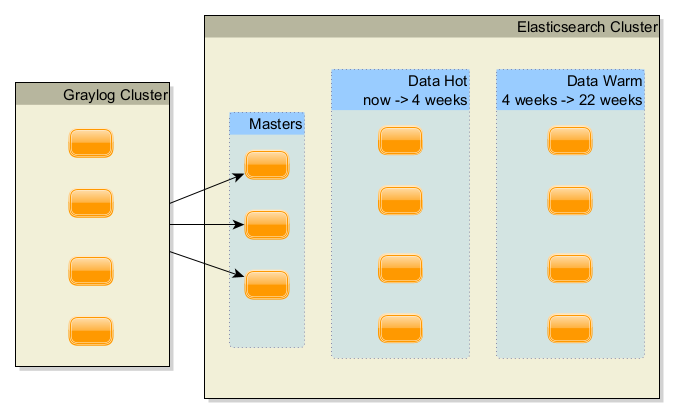
I have an index rotation based on time, one indice per week.
With ILM I have 4 weeks of logs on the Hot data nodes.
After 4 weeks the indices are moved to the Warm nodes.
On the Warm nodes, 22 weeks are keeped, the older are dropped.
In the indice template, the "source" field who contain the hostname who sent the log is set as "fieldata"
"source": {
"fielddata": true,
"analyzer": "analyzer_keyword",
"type": "text"
},
Some example of hostnames I have in the "source" field :
pirv-siem-relay-01
dirv-monitoring-centreon-02
eidv-vrouter-unitary11-ma-02
My question is the following :
When I run a dashboard in Graylog on the LAST 5 MINUTES of logs, which is doing aggregration based on the "source" field I have a fielddata memory error on the Warm nodes :
[2022-05-03T18:17:17,946][WARN ][o.e.i.b.fielddata ] [eirv-siem-es-07] [fielddata] New used memory 7165570335 [6.6gb] for data of [source] would be larger than configured breaker: 6871947673 [6.3gb], breaking
If I enlarge the HEAP size only on the Warm nodes, the error disappears.
I understand the error, but what i don't understand is why the error is happening on the Warm nodes, for a request that are only searching in the last 5 minutes of logs.
The request is not supposed to run only on the Hot nodes ?
Thanks for reading.