I am ingesting 40 GB data at a time after deleting the previous data for the same period. I have to delete before since new version might be missing some rows. Since update wouldn't remove he unwanted rows, am deleting before re-ingesting. Can deleting right before ingestion can performance issues in writing data?
Cluster details:
7 node x r4.2xlarge (8 vCPU, 61 GB - 32 assigned to ES) on AWS
ES 6.0 30GB per node (not 32GB)
210GB memory / 5TB disk space
Linux Red Hat 4.8.3-9 4.4.15-25.57.amzn1.x86_64 Java 1.8
Yes we plan to make that change. But we have something in production already, where we are facing slow writes and am guessing it is because of the deletion we do juts before. So I am looking for how to get this sorted for now and we will fix it permanently by having time based indices
@dadoonet thanks for your reply. Can having multiple indices impact on performance? For example currently we have around 2 TB data in 28 primary shards. If we divide indices by week (lets day) and we have 52 indices. so querying 6 months of data, it will query 26*5 = 130 shards or may be it is better to have lesser shards per index.
We started with 7 shards but our data was growing fast and we reached like 120GB per shard. We started facing problems with it with ingestion and slow read performance when cluster is relocating etc. To keep 50GB/shard, we chose 28 shards.
Ok, I realised we can't easily split by date because we do parent/child to do absolute distinct (no approximations but accurate) which normally ES would not allow since it uses hyperloglog with cardinality 40,000. Probably, ES was a wrong choice for this. a) there was no way to do absolute distinct for higher cardinality, we worked around with parent/child but its not great b) Because of this we cannot even split the index.
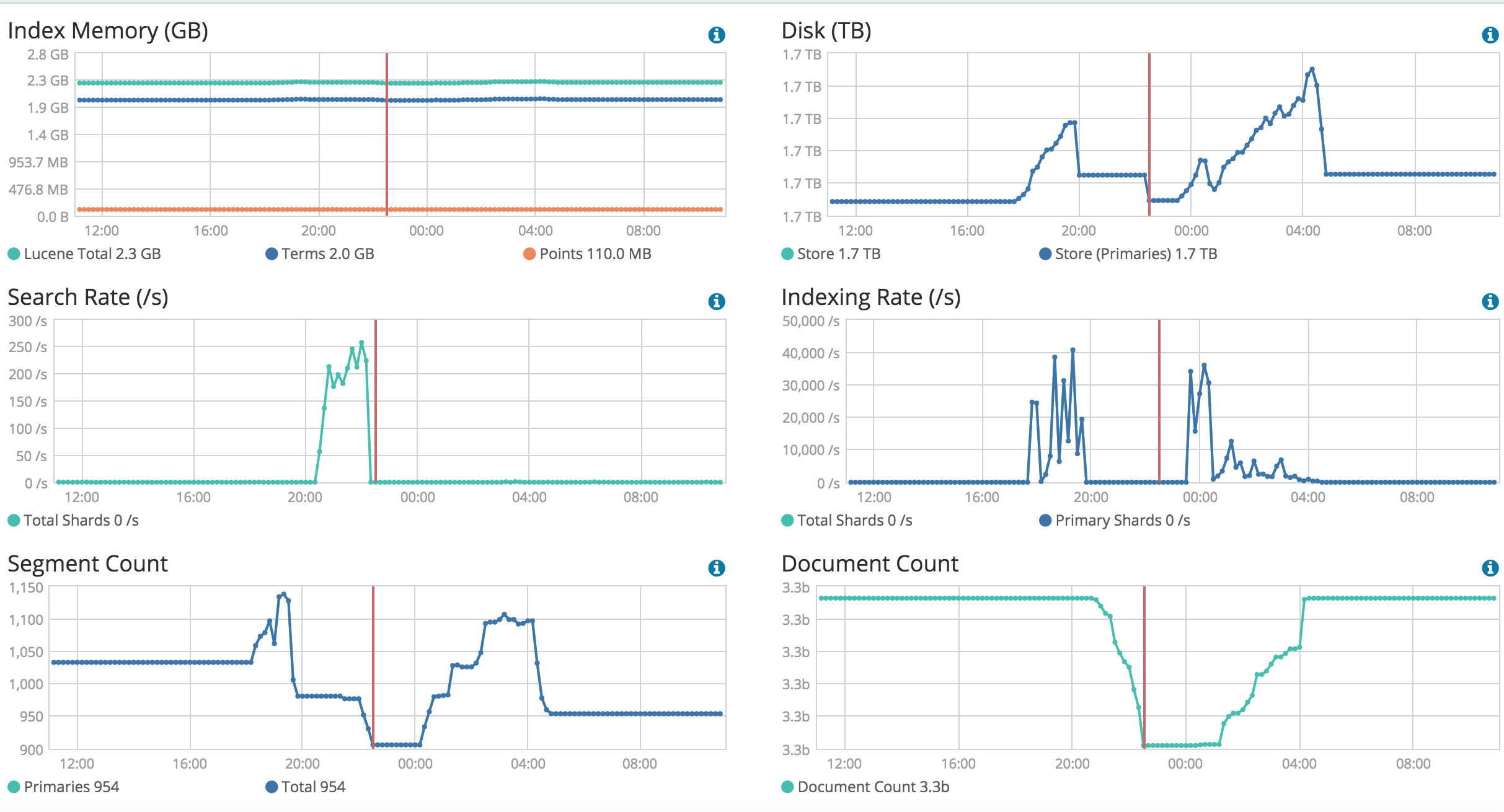
So with current problem of deleting and re-ingesting, I see the difference in indexing speed when 1) Just ingest data 2) I delete and ingest. In the graph below index rate is consistent in case 1 and slows down in 2
Can you please help me understand what causes this and if there can anything done to sort this for now (for example, may be deleting the data in advance)? Thank you
ah no we didn't force merge. Thanks for pointing! Probably that leads to this overlap between deletion and ingestion. probably we should call this api https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-forcemerge.html after after deletion and before re-ingesting new data? I am guessing could be a heavy operation to do over 2-3 TB data.
Also we run deletion and ingestion with refresh_interval = -1. Does that needs to be reset as well or force merge would be sufficient?
We have 4 ingestion jobs running weekly across 2 indices. We set refresh_interval=-1 before these set of jobs runs and reset it to refresh_interval=1s at the end.
Actually we have tried force merge before (with only_expunge_deletes) when our cluster went into yellow state (that time we had very big shards, holding around 220GB data each so that could be a reason), we ended up reindexing to a new index with took around 2 days. From that experience we realised this is an heavy operation and little concerned to do it every week.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.