Elasticsearch version ( bin/elasticsearch --version ): 7.2.0
Plugins installed :
JVM version ( java -version ): JDK 12 (bundled)
OS version ( uname -a if on a Unix-like system): Ubuntu 14.04.5 LTS
This is in reference to https://github.com/elastic/elasticsearch/issues/55013
Description of the problem including expected versus actual behaviour :
We recently migrated to 7.2.0 ES and setup a backup cron that takes snapshot of production every 2hr and does a restore. The restore however takes around 2-3hrs to complete. Whereas in 1.7 earlier it used to finish within a minute
During restore, what we've observed is that, cat/indices doesn't list all the indices. At first we thought if restore is deleting indices? That would be bad. But from disk utilization graphs, that kind of wasn't the case. However there was a good amount of drop in used space in our disk (roughly half as shown here)
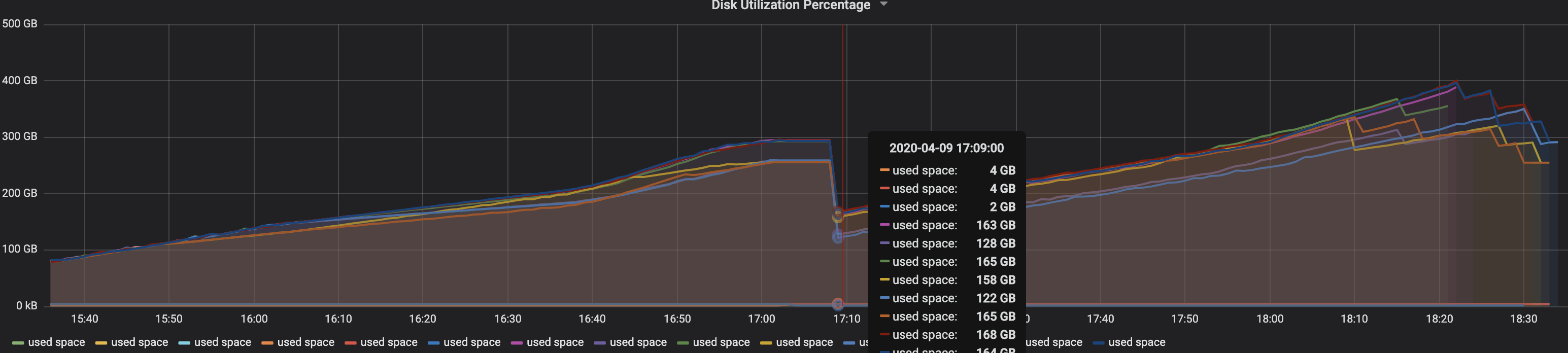
At time 17:09, the restore started and if you see, the disk usage dropped by almost half from ~300GB to ~150GB
cat/shards show all the primaries are in INITIALIZED state
sample line from cat/recovery
issues-index 0 4m snapshot index n/a n/a x.x.x.x es7advcl01-09 es7advcl02 snapshot_200409120001 313 9 2.9% 319 36982790918 2508329227 6.8% 37255110711 0 0 100.0%
issues-index 1 4m snapshot index n/a n/a x.x.x.x es7advcl01-13 es7advcl02 snapshot_200409120001 331 9 2.7% 356 35062077787 2528382202 7.2% 37816732630 0 0 100.0%
issues-index 2 4m snapshot index n/a n/a x.x.x.x es7advcl01-11 es7advcl02 snapshot_200409120001 277 1 0.4% 308 31645896495 2528871414 8.0% 37250260213 0 0 100.0%
issues-index 3 4m snapshot index n/a n/a x.x.x.x es7advcl01-07 es7advcl02 snapshot_200409120001 278 9 3.2% 278 37237367179 2505543480 6.7% 37237367179 0 0 100.0%
explain api on a primary shard
{
"index": "issues-index",
"shard": 0,
"primary": true,
"current_state": "initializing",
"unassigned_info": {
"reason": "EXISTING_INDEX_RESTORED",
"at": "2020-04-09T13:20:41.435Z",
"details": "restore_source[es7advcl02/snapshot_200409120001]",
"last_allocation_status": "awaiting_info"
},
"current_node": {
"id": "0ccKssgEQmayndGpJA0Kfg",
"name": "es7advcl01-09",
"transport_address": "x.x.x.x:xxxx",
"attributes": {
"nodetag": "issues",
"ml.machine_memory": "64388841472",
"ml.max_open_jobs": "20",
"xpack.installed": "true"
}
},
"explanation": "the shard is in the process of initializing on node [es7advcl01-09], wait until initialization has completed"
}
sample index/_recovery response
{
"issues-index": {
"shards": [
{
"id": 16,
"type": "SNAPSHOT",
"stage": "INDEX",
"primary": true,
"start_time_in_millis": 1586438441641,
"total_time_in_millis": 2599243,
"source": {
"repository": "es7advcl02",
"snapshot": "snapshot_200409120001",
"version": "7.2.0",
"index": "issues-index",
"restoreUUID": "6cdxLeuWQmaqRNkhXWupKw"
},
"index": {
"size": {
"total_in_bytes": 36833533836,
"reused_in_bytes": 393555386,
"recovered_in_bytes": 27281694426,
"percent": "74.9%"
},
"files": {
"total": 337,
"reused": 6,
"recovered": 108,
"percent": "32.6%"
},
"total_time_in_millis": 2599240,
"source_throttle_time_in_millis": 0,
"target_throttle_time_in_millis": 0
},
"translog": {
"recovered": 0,
"total": 0,
"percent": "100.0%",
"total_on_start": 0,
"total_time_in_millis": 0
},
"verify_index": {
"check_index_time_in_millis": 0,
"total_time_in_millis": 0
}
},
{
"id": 24,
"type": "SNAPSHOT",
"stage": "INDEX",
"primary": true,
"start_time_in_millis": 1586438441644,
"total_time_in_millis": 2599241,
"source": {
"repository": "es7advcl02",
"snapshot": "snapshot_200409120001",
"version": "7.2.0",
"index": "issues-index",
"restoreUUID": "6cdxLeuWQmaqRNkhXWupKw"
},
"index": {
"size": {
"total_in_bytes": 37394586004,
"reused_in_bytes": 384374051,
"recovered_in_bytes": 27237551760,
"percent": "73.6%"
},
"files": {
"total": 337,
"reused": 6,
"recovered": 117,
"percent": "35.3%"
},
"total_time_in_millis": 2599238,
"source_throttle_time_in_millis": 0,
"target_throttle_time_in_millis": 0
},
"translog": {
"recovered": 0,
"total": 0,
"percent": "100.0%",
"total_on_start": 0,
"total_time_in_millis": 0
},
"verify_index": {
"check_index_time_in_millis": 0,
"total_time_in_millis": 0
}
},
{
"id": 8,
"type": "SNAPSHOT",
"stage": "INDEX",
"primary": true,
"start_time_in_millis": 1586438441638,
"total_time_in_millis": 2599247,
"source": {
"repository": "es7advcl02",
"snapshot": "snapshot_200409120001",
"version": "7.2.0",
"index": "issues-index",
"restoreUUID": "6cdxLeuWQmaqRNkhXWupKw"
},
"index": {
"size": {
"total_in_bytes": 37646982630,
"reused_in_bytes": 0,
"recovered_in_bytes": 27241548911,
"percent": "72.4%"
},
"files": {
"total": 326,
"reused": 0,
"recovered": 119,
"percent": "36.5%"
},
"total_time_in_millis": 2599244,
"source_throttle_time_in_millis": 0,
"target_throttle_time_in_millis": 0
},
"translog": {
"recovered": 0,
"total": 0,
"percent": "100.0%",
"total_on_start": 0,
"total_time_in_millis": 0
},
"verify_index": {
"check_index_time_in_millis": 0,
"total_time_in_millis": 0
}
}
]
}
}
index.{files,size}.reused seems to be very less for every shard
Here are some things that happened while snapshots were taken every 2hrs
- We had the index setup on production
- Snapshot was taken of this index with some data
- We figured out some bug in mapping
- We deleted the index and recreated with same name
- All this time snapshots were still happening
- We indexed 2TB of data as part of our migration. Settings like refresh interval and replicas=0 were set and were reverted back to default once migration was done.
forcemergeAPI was called after indexing completed - Snapshots kept on happening
- Restores started to slow down. I understand the very first restore can be slow. But I expect subsequent restores to be fast because they are incremental. We see slowness in subsequent restores as well which is undesirable as a DR strategy
We restore using
curl host:port/_snapshot/repo/snapshot-name/_restore
We also tried cleaning the entire backup cluster (removed data folder as well and do a fresh restore), but that didnt help either
We also tried
curl host:port/_snapshot/repo/snapshot-name/_restore
{
"include_global_state": true
}
We make use of node attributes on production cluster, here is the index settings
{
"issues-index": {
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"nodetag": "issues"
}
}
}
}
}
}
}
for remaining indices, nodetag has the value of nonissues . Both backup and production have the same set of attributes so this is not a concern
I also just now confirmed that, during restore ES does not move primary shards to other nodes. This kind of rules out rebalancing happening due to presence of nodetag attribute above?