I'm looking for an advice for index update strategy.
I'd like to import data from SQL Server to Elasticsearch in batches.
Let's assume we have data in this format in SQL:
ProjectID ProductID
---------------------------------
1 1
1 2
1 3
1 4
1 5
2 6
2 7
2 8
2 9
2 10
What happens in SQL is that we wipe data from this table and reinsert data from staging tables into it every weekend on ProjectID basis. I'd like to keep this table in sync with Elasticsearch indices, but cannot think of a strategy.
I was thinking about having index templates and storing each project data in seperate indice, pretty much like that
- data_project_1
- data_project_2
- etc.
I could delete indice for a specific project and then just to re-pump that data from SQL Server using logtash, but then I'd have some data discrepancies and user wouldn't be able to perform searches on that project data for some time (well, this in the end might be acceptable anyway). But how would I delete indice using tools that Elastic provides? Indice needs to be dropped and recreated on demand (most likely having some flag in SQL Server), so there's no use of TTL in indice.
It seems that Curator is suited for tasks like that, but it doesn't seem that it can read from SQL Server.
Any advices?
Can you say something about the numbers here?
Numbers of projects?
Records per project? (median, max)
Do all projects change every weekend?
Percent of project records that change when updates are applied?
Dropping whole indexes is the most efficient form of mass-delete but equally you shouldn't have too many indices as this is inefficient. The right strategy (essentially patch or rebuild) depends on the answers to some of these questions.
Cheers
Mark
Hi Mark,
sure, please see these figures:
ProjectID RecordCount MaxCount MinCount AvgCount
--------- ----------- -------- -------- --------
1 4831835 6492750 7753 643131
2 81007 6492750 7753 643131
3 26941 6492750 7753 643131
4 371923 6492750 7753 643131
5 17905 6492750 7753 643131
6 7753 6492750 7753 643131
7 526569 6492750 7753 643131
8 2172419 6492750 7753 643131
9 37008 6492750 7753 643131
10 110930 6492750 7753 643131
11 606660 6492750 7753 643131
12 37978 6492750 7753 643131
13 1701177 6492750 7753 643131
14 223150 6492750 7753 643131
15 292052 6492750 7753 643131
16 350040 6492750 7753 643131
17 619659 6492750 7753 643131
18 297291 6492750 7753 643131
19 156832 6492750 7753 643131
20 358034 6492750 7753 643131
21 212467 6492750 7753 643131
22 86441 6492750 7753 643131
23 6492750 6492750 7753 643131
24 96780 6492750 7753 643131
25 180985 6492750 7753 643131
26 950142 6492750 7753 643131
27 15126 6492750 7753 643131
28 2103449 6492750 7753 643131
29 210237 6492750 7753 643131
30 492430 6492750 7753 643131
31 168670 6492750 7753 643131
32 570010 6492750 7753 643131
33 19285 6492750 7753 643131
34 132484 6492750 7753 643131
35 89195 6492750 7753 643131
36 1777734 6492750 7753 643131
37 96898 6492750 7753 643131
38 11010 6492750 7753 643131
39 1724006 6492750 7753 643131
40 28381 6492750 7753 643131
41 99449 6492750 7753 643131
42 100781 6492750 7753 643131
43 168784 6492750 7753 643131
44 167828 6492750 7753 643131
45 645294 6492750 7753 643131
46 116276 6492750 7753 643131
- So we have now 46 of them in total with given amount of records per project.
- No, not all projects change every weekend. This number varies from 3 to about 8. Usually it's around 5.
- There's actually not much that changes in those tables, I'd say usually less than 10% of the actual data, perhaps 15%.
- We run these updates in SQL Server only on the weekends. There are some very rare scenarios when we do that in the working week, but that's a very rare case.
Of course some new publications might happen, but that's pretty much same as index rebuild, except that we don't have to delete anything.
Let me know if you need extra details.
Thanks,
Evaldas
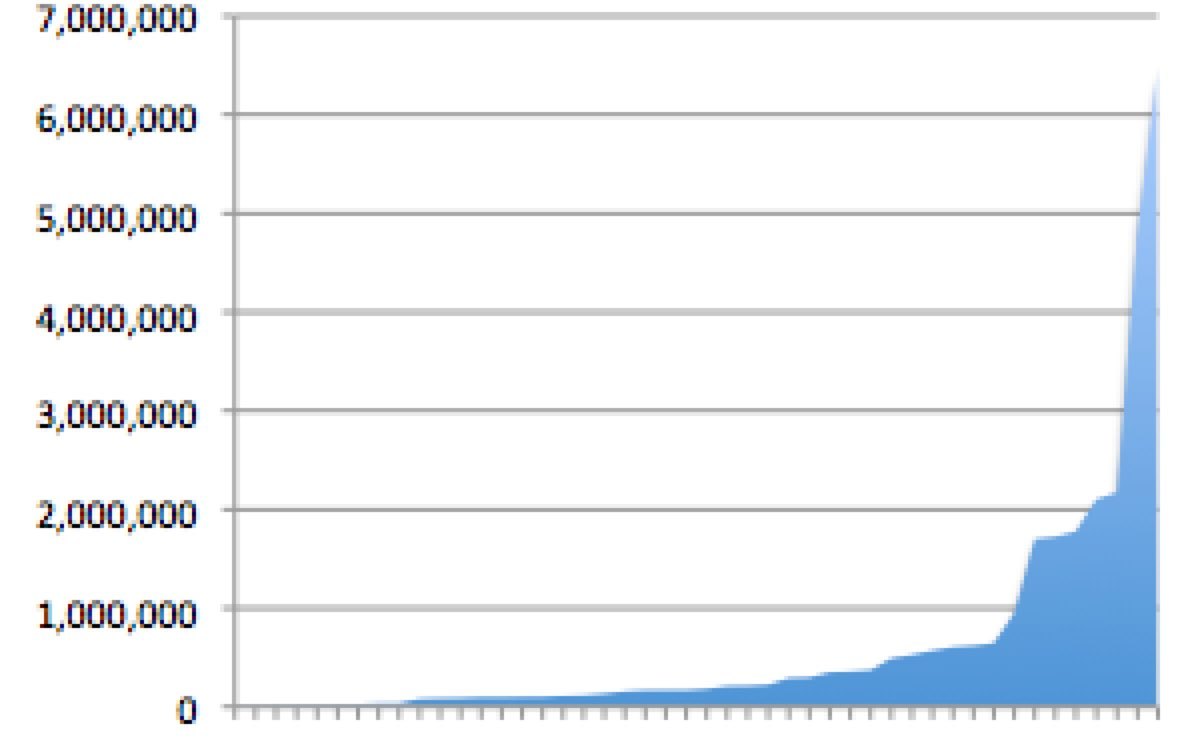
OK so there's a small number of projects but they vary a lot in size:
Overall though there's not a huge amount of data so you should easily fit it in one index. The question then is whether to patch or rebuild the index each weekend from the SQL database. A full rebuild is easiest to configure but may take some time to pull from the db (you can use an elasticsearch alias to manage the flip over between the old and the new index). Alternatively a patch is typically achieved by pulling across only records updated or inserted since the last run using timestamps. Deletes may require a special table populated by a trigger every time a record is deleted. Check out this project to help manage the synching process: https://github.com/jprante/elasticsearch-jdbc
Cheers
Mark
Thanks Mark for your suggestions.
I'll check everything out.
Thanks,
Evaldas