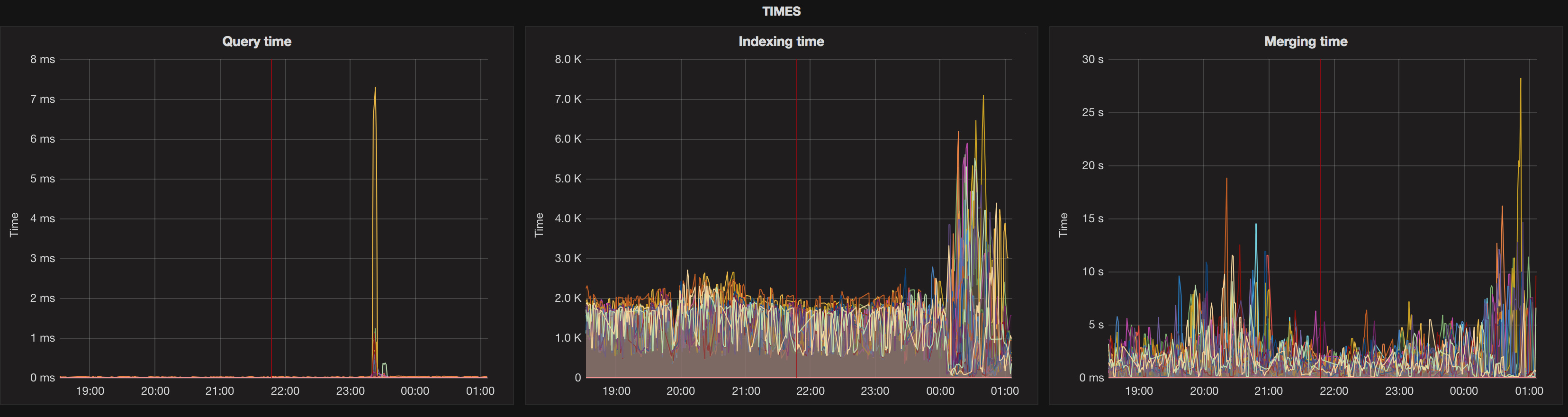
Blockquote
"_nodes" : {
"total" : 21,
"successful" : 21,
"failed" : 0
},
"cluster_name" : "stage-escluster",
"timestamp" : 1510664066932,
"status" : "green",
"indices" : {
"count" : 1080,
"shards" : {
"total" : 6974,
"primaries" : 3487,
"replication" : 1.0,
"index" : {
"shards" : {
"min" : 2,
"max" : 60,
"avg" : 6.457407407407407
},
"primaries" : {
"min" : 1,
"max" : 30,
"avg" : 3.2287037037037036
},
"replication" : {
"min" : 1.0,
"max" : 1.0,
"avg" : 1.0
}
}
},
"docs" : {
"count" : 5130705993,
"deleted" : 1996
},
"store" : {
"size_in_bytes" : 14100406765796,
"throttle_time_in_millis" : 0
},
"fielddata" : {
"memory_size_in_bytes" : 0,
"evictions" : 0
},
"query_cache" : {
"memory_size_in_bytes" : 0,
"total_count" : 0,
"hit_count" : 0,
"miss_count" : 0,
"cache_size" : 0,
"cache_count" : 0,
"evictions" : 0
},
"completion" : {
"size_in_bytes" : 0
},
"segments" : {
"count" : 118255,
"memory_in_bytes" : 26172275408,
"terms_memory_in_bytes" : 19511538176,
"stored_fields_memory_in_bytes" : 4999585136,
"term_vectors_memory_in_bytes" : 0,
"norms_memory_in_bytes" : 15136384,
"points_memory_in_bytes" : 1058100340,
"doc_values_memory_in_bytes" : 587915372,
"index_writer_memory_in_bytes" : 7610750628,
"version_map_memory_in_bytes" : 85053111,
"fixed_bit_set_memory_in_bytes" : 0,
"max_unsafe_auto_id_timestamp" : -1,
"file_sizes" : { }
}
},
"nodes" : {
"count" : {
"total" : 21,
"data" : 18,
"coordinating_only" : 0,
"master" : 3,
"ingest" : 21
},
"versions" : [
"5.5.0"
],
"os" : {
"available_processors" : 156,
"allocated_processors" : 156,
"names" : [
{
"name" : "Linux",
"count" : 21
}
],
"mem" : {
"total_in_bytes" : 648554434560,
"free_in_bytes" : 15388495872,
"used_in_bytes" : 633165938688,
"free_percent" : 2,
"used_percent" : 98
}
},
"process" : {
"cpu" : {
"percent" : 1187
},
"open_file_descriptors" : {
"min" : 977,
"max" : 1745,
"avg" : 1618
}
},
"jvm" : {
"max_uptime_in_millis" : 1532237262,
"versions" : [
{
"version" : "1.8.0_31",
"vm_name" : "Java HotSpot(TM) 64-Bit Server VM",
"vm_version" : "25.31-b07",
"vm_vendor" : "Oracle Corporation",
"count" : 21
}
],
"mem" : {
"heap_used_in_bytes" : 164761887000,
"heap_max_in_bytes" : 333647708160
},
"threads" : 2443
},
"fs" : {
"total_in_bytes" : 39368577171456,
"free_in_bytes" : 10708432044032,
"available_in_bytes" : 8729318752256
},
"plugins" : [
{
"name" : "discovery-ec2",
"version" : "5.5.0",
"description" : "The EC2 discovery plugin allows to use AWS API for the unicast discovery mechanism.",
"classname" : "org.elasticsearch.discovery.ec2.Ec2DiscoveryPlugin",
"has_native_controller" : false
},
{
"name" : "x-pack",
"version" : "5.5.0",
"description" : "Elasticsearch Expanded Pack Plugin",
"classname" : "org.elasticsearch.xpack.XPackPlugin",
"has_native_controller" : true
}
],
"network_types" : {
"transport_types" : {
"netty4" : 21
},
"http_types" : {
"netty4" : 21
}
}
}
}