Hello Team,
We can create embeddings using a pipeline with 1 ML node. But, when we add another node, it seems like none of the documents gets ingested through the pipeline. Attached is the reference.
note: using simulation API for one document works fine. But when the documents are in batches it fails.

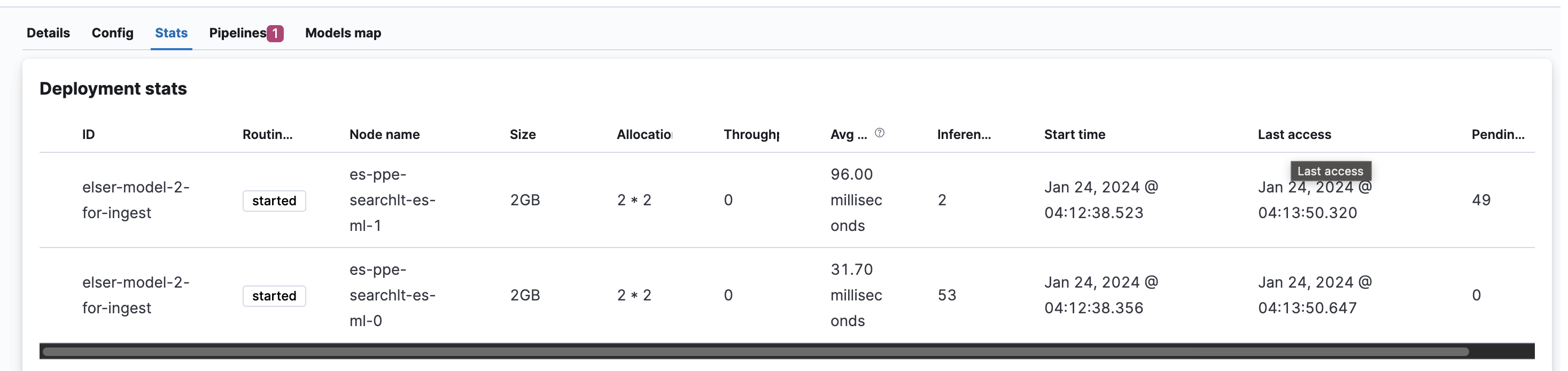
Can you view how we can troubleshoot errors while ingesting through the pipeline? We have an "on_failure" processor but it does not log anything in this case, so we are clueless about what is happening and unable to ingest any data to index.
"on_failure": [
{
"set": {
"description": "Index document to '<index>'",
"field": "_index",
"value": "{{{_index}}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{ _ingest.on_failure_processor_type }} processor in pipeline {{ _ingest.on_failure_pipeline }} failed with message: {{ _ingest.on_failure_message }}"
}
}
]