Hi,
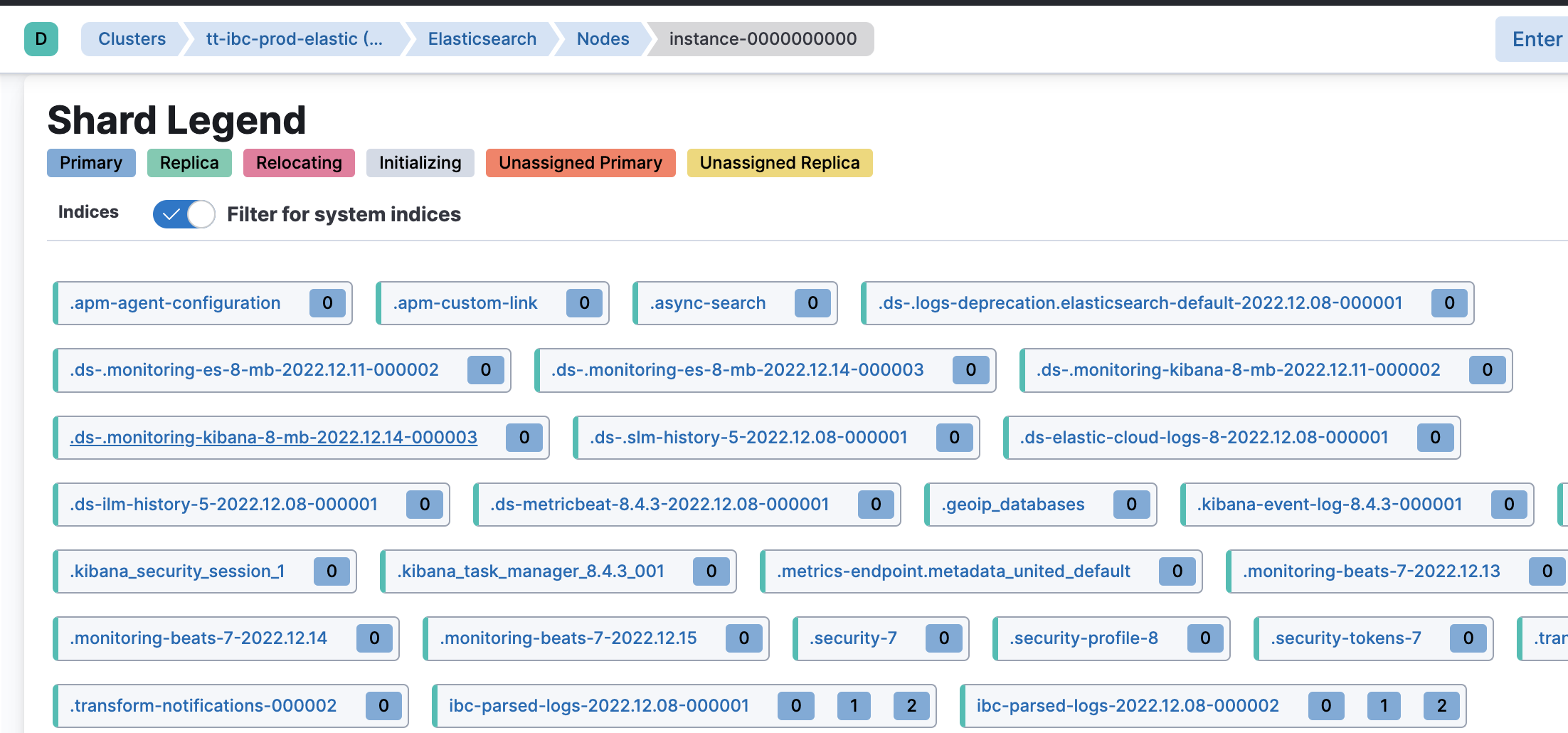
We have an 8.x ES cluster running on Elastic cloud, All seems to be working ok except that a few internal monitoring indices have one shard marked as UNASSIGNED and this causes the cluster state to be YELLOW, all the time...
I followed this Guide to troubleshoot:
Get info about shards - find which ones are unassigned:
GET _cat/shards?v=true&h=index,shard,prirep,state,node,unassigned.reason&s=state
Response as of Dec 14, 9:33PM EST:
index shard prirep state node unassigned.reason
.ds-.monitoring-es-8-mb-2022.12.14-000003 0 r UNASSIGNED INDEX_CREATED
.ds-.monitoring-kibana-8-mb-2022.12.14-000003 0 r UNASSIGNED INDEX_CREATED
Get more details about the allocation for the specific index/shard:
GET _cluster/allocation/explain
{
"index": ".ds-.monitoring-es-8-mb-2022.12.14-000003",
"shard": 0,
"primary": false
}
Result:
{
"index": ".ds-.monitoring-es-8-mb-2022.12.14-000003",
"shard": 0,
"primary": false,
"current_state": "unassigned",
"unassigned_info": {
"reason": "INDEX_CREATED",
"at": "2022-12-14T21:45:50.221Z",
"last_allocation_status": "no_attempt"
},
"can_allocate": "no",
"allocate_explanation": "Elasticsearch isn't allowed to allocate this shard to any of the nodes in the cluster. Choose a node to which you expect this shard to be allocated, find this node in the node-by-node explanation, and address the reasons which prevent Elasticsearch from allocating this shard there.",
"node_allocation_decisions": [
{
"node_id": "hYTLxs3cQwSSQNRWNCVHJg",
"node_name": "instance-0000000001",
"transport_address": "10.xxx:19240",
"node_attributes": {
"logical_availability_zone": "zone-0",
"server_name": "instance-0000000001.aa7f0380c25d414f810f9a23d173130b",
"availability_zone": "us-east4-a",
"xpack.installed": "true",
"data": "warm",
"instance_configuration": "gcp.es.datawarm.n2.68x10x190",
"region": "unknown-region"
},
"node_decision": "no",
"weight_ranking": 1,
"deciders": [
{
"decider": "data_tier",
"decision": "NO",
"explanation": "index has a preference for tiers [data_hot] and node does not meet the required [data_hot] tier"
}
]
},
{
"node_id": "RR_pUkQdRR2HqwjMlNhtVg",
"node_name": "instance-0000000000",
"transport_address": "10.xxx:19870",
"node_attributes": {
"region": "unknown-region",
"instance_configuration": "gcp.es.datahot.n2.68x10x45",
"server_name": "instance-0000000000.aa7f0380c25d414f810f9a23d173130b",
"data": "hot",
"xpack.installed": "true",
"logical_availability_zone": "zone-0",
"availability_zone": "us-east4-a"
},
"node_decision": "no",
"weight_ranking": 2,
"deciders": [
{
"decider": "same_shard",
"decision": "NO",
"explanation": "a copy of this shard is already allocated to this node [[.ds-.monitoring-es-8-mb-2022.12.14-000003][0], node[RR_pUkQdRR2HqwjMlNhtVg], [P], s[STARTED], a[id=fxfbSsCnTq-DGvTI4laIPg]]"
}
]
}
]
}
This part seems to offer a promising reason:
"explanation": "index has a preference for tiers [data_hot] and node does not meet the required [data_hot] tier"
However, I'm not sure how to solve this - since I am not controlling templates or ILMs for these internal indices and do not set some custom policies for shard allocations ... Whatever is the default policy - it should be used as is.
My cluster config:
-- 2 nodes
-- 1 availability zone
-- Hot and Warm storage only, no cold
Any advise on how to troubleshoot this further would be very appreciated!
Thank you!
Marina