Hello,
I see scripted fields has been deprecated in 7.13 and it is suggested that we use runtime fields.
I was wondering if it is possible to add a runtime field which calculates the ratio of two different column values in the same row?
The following is a simple example:
I can generate a table which has the rows separated by Call Center name and two columns which are the sum of Incoming calls and sum of Outgoing Calls.
The next two columns are the ones I would like to generate:
-
% Incoming Calls = sum Incoming calls / (sum Incoming calls + sum of Outgoing Calls)
-
% Outgoing Calls = sum of Outgoing Calls / (sum of Incoming calls + sum of Outgoing Calls)
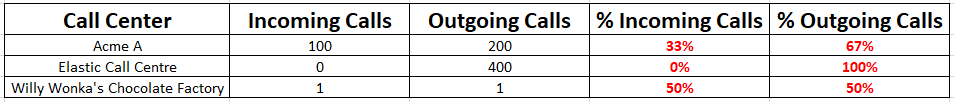
Thanks in advance for your help!
Mike