yes, we have it so far that way (all synonyms together for whole corpus), but for legal/approval reasons it has to be separated.
I have technically explored option #2 (search analyzers) and it looks it doesn't work well for multi-token synonyms.
Here's my case:
Firstly defining analyzers, synonyms (multi-tokens - used contraction approach)
Multi-token synonyms defined only for "ire_exact" analyzer (quoted search).
SETTINGS:
"analysis": {
"filter": {
"lh_synonym_regular": {
"type": "synonym",
"synonyms": [
"applicable_law,governing_law",
"effective_date,commencement_date,inception_date,indemnity_period"
]
},
"lh_synonym_contraction": {
"type": "synonym",
"synonyms": [
"effective date => effective_date,effective date",
"commencement date => commencement_date,commencement date",
"inception date => inception_date,inception date",
...
"analyzer": {
"ire_regular": {
"filter": [
"ascii_folding",
"lowercase",
"lh_synonym_single",
"stop",
"irregular_stems",
"prevent_stems",
"english_stemmer"
],
"char_filter": [
"OCR_filter",
"special_chars_regular"
],
"tokenizer": "standard"
},
"ire_exact": {
"filter": [
"lowercase",
"lh_synonym_contraction",
"lh_synonym_regular"
],
"char_filter": [
"OCR_filter",
"special_chars_exact"
],
"tokenizer": "whitespace"
}
MAPPINGS:
"properties": {
"content": {
"properties": {
"DOC_TEXT": {
"type": "text",
"fields": {
"exact": {
"type": "text",
"term_vector": "with_positions_offsets"
}
},
"term_vector": "with_positions_offsets"
},
Inserting test data:
PUT treaty_scenario2a/_doc/testing1
{
"content":{
"DOC_TEXT":"document with inception date mentioned"
}
}
PUT treaty_scenario2a/_doc/testing2
{
"content":{
"DOC_TEXT":"an effective date document"
}
}
QUERY:
- didn't match "effective date"
GET treaty_scenario2a/_explain/testing2?q=content.DOC_TEXT.exact:"inception date"&analyzer=ire_exact
- didn't match "inception date"
GET treaty_scenario2a/_explain/testing1?q=content.DOC_TEXT.exact:"effective date"&analyzer=ire_exact
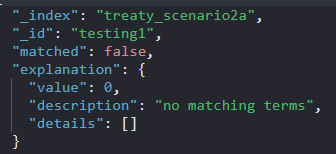
I was aiming to get it work this way (provide BU specific ire_regular and ire_exact analyzers to query_string):
GET treaty_scenario2a/_search?q=_id:testing2
{
"explain": true,
"_source": ["content.DOC_TEXT"],
"query": {
"query_string": {
"default_field": "content.DOC_TEXT",
"query": "\"inception date\"",
"analyzer": "ire_regular",
"quote_field_suffix": ".exact",
"quote_analyzer": "ire_exact"
}
},
"highlight": {
"fields": {
"content.DOC_TEXT": {
"type": "fvh",
"matched_fields": [
"content.DOC_TEXT",
"content.DOC_TEXT.exact"
],
"fragment_size": 1000,
"no_match_size": 0,
"number_of_fragments": 1,
"boundary_scanner": "chars",
"fragmenter": "span"
},
"content.DOC_TEXT_PROX": {
"highlight_query": {
"query_string": {
"fields": [
"content.DOC_TEXT.exact"
],
"analyzer": "ire_exact",
"query": "\"inception date\""
}
},
"type": "unified",
"boundary_scanner": "sentence",
"fragment_size": 1000,
"number_of_fragments": 1,
"no_match_size": 1000,
"fragmenter": "span"
}
}
}
}
But it seems, it cannot match/highlight multi-word synonyms on SEARCH time, since the synonyms are not indexed. If you would have some solution to that case, I would be happy to hear about it.
Thanks