If my understanding is correct... we would require this data forever in the server. There were chances that they might not require the data - will get back on this.
When you say how long do you need to keep data in the cluster - do you mean we have to remove the old data from the data nodes after some period of time ?
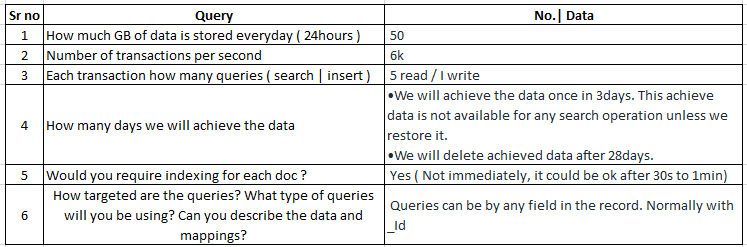
Not for bulk insert. There were multiple types of insertion here.
We have provided an api in nodes which will trigger elastic servers.
These api’s are called by third party customers ( multiple customers ) - they might upload excel sheet in their portal and trigger our api for each row.
Same api is available for third party customers in which they will do single transaction. We will receive requests on parallel.
Combining above 2 scenarios we would get around 9k transactions per second.
If you do not use bulk inserts and require the indexed document to be searchable immediately you will make indexing very inefficient. This basically goes against most recommendations in this guide around optimizing indexing speed. This will result in a lot of small segments being generated and requiring merging which will put a lot of load on the cluster and result in a lot of disk I/O. In itself indexing 9k documents of 1kB in size is achievable but might require more cluster resources and very fast storage.
You also mention a quite high search rate. In order to optimize the search rate supported by the cluster you ideally want to have immutable data that is fully kept in the operating system file cache. Even if there was no indexing going on you state that you are likely to have very large amounts of data. If this does not fit in the cache it will generate a lot of disk I/O which will lead to longer latencies and reduced query throughput.
If you add these two together you see that the indexing will add new data, which will affect the page cache and make it less efficient. I therefore do not think Elasticsearch is suitable for this use case (unless you work with the requirements) and if you were to try make it work you would need a lot of hardware.
That sounds much more reasonable but you will need fast disks and enough RAM to allow most data on disk to be cached. In order to determine whether you can meet the SLAs or not you will need to benchmark using realistic data and operations. Sounds feasible with correct timing and bulk indexing.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.