I'll start off with a brief summary of the setup:
Single node, ES 6.4.2, Debian 9 with OpenJDK 1.8.0_212
+/- 500 indexes, 2500 shards, 12M documents, 3.5 GB data.
x-pack monitoring, 60s samples, 7 days retention
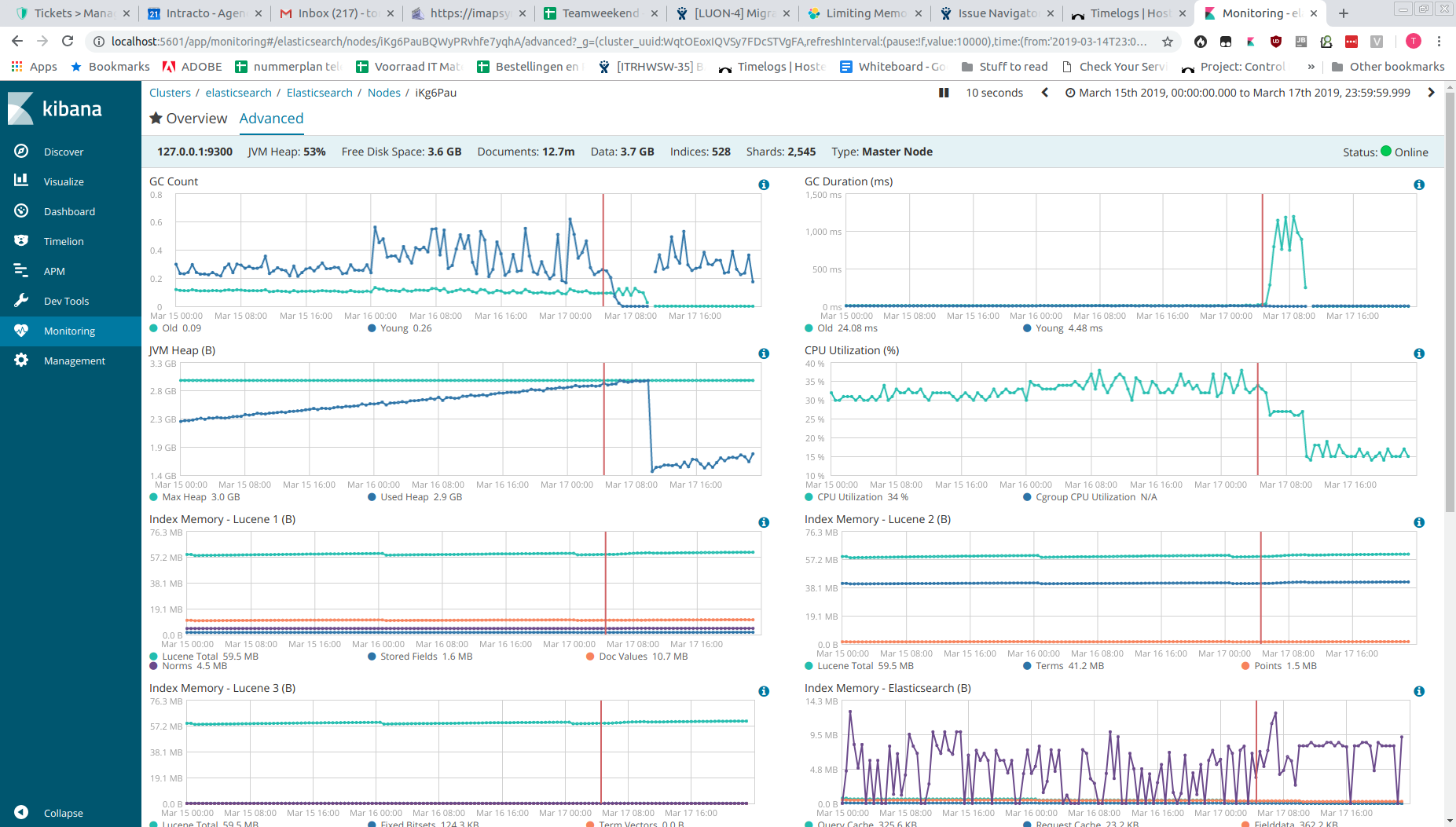
What we are experiencing is that the JVM heap is slowly creeping up. Once it hits 100%, latency, segment count and GC duration go up, where GC Young drops to 0. Queries take very long causing the website that uses the ES to become unresponsive/unusable. Restarting Elasticsearch solves the problem.
Hi @TomCan, there is a memory leak bug that affects version 6.4.1 through 6.5.2, fixed by #36308. I suggest upgrading to a version ≥ 6.5.3 and report back if the problem persists.
Hi @DavidTurner, thanks for pointing that out. We've upgrade the server to 6.6 yesterday and it has been running for a day now. Memory usage is significantly lower than with 6.4 and it's very stable.
Hi @DavidTurner,
I had exact same problem with version 6.4.3 and upgraded it to 6.6.2 hoping that it will solve, But it didnt help, I am still facing the issue, that my memory consumption slowly goes high, Gc works couple of times and pulls it back, but third time, Memory consumption spikes, holds constantly at 99% and the node eventually goes down becoming unresponsive for sometime.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.