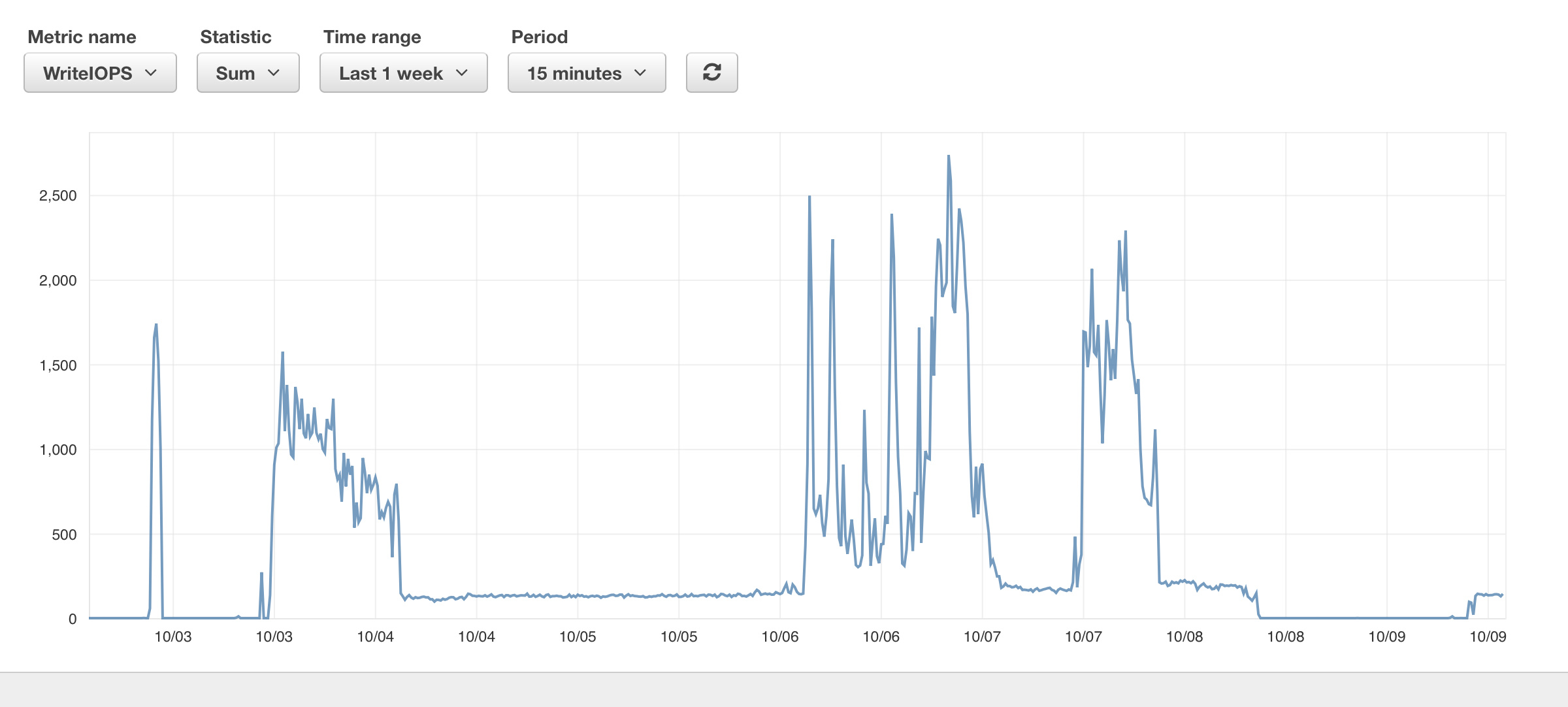
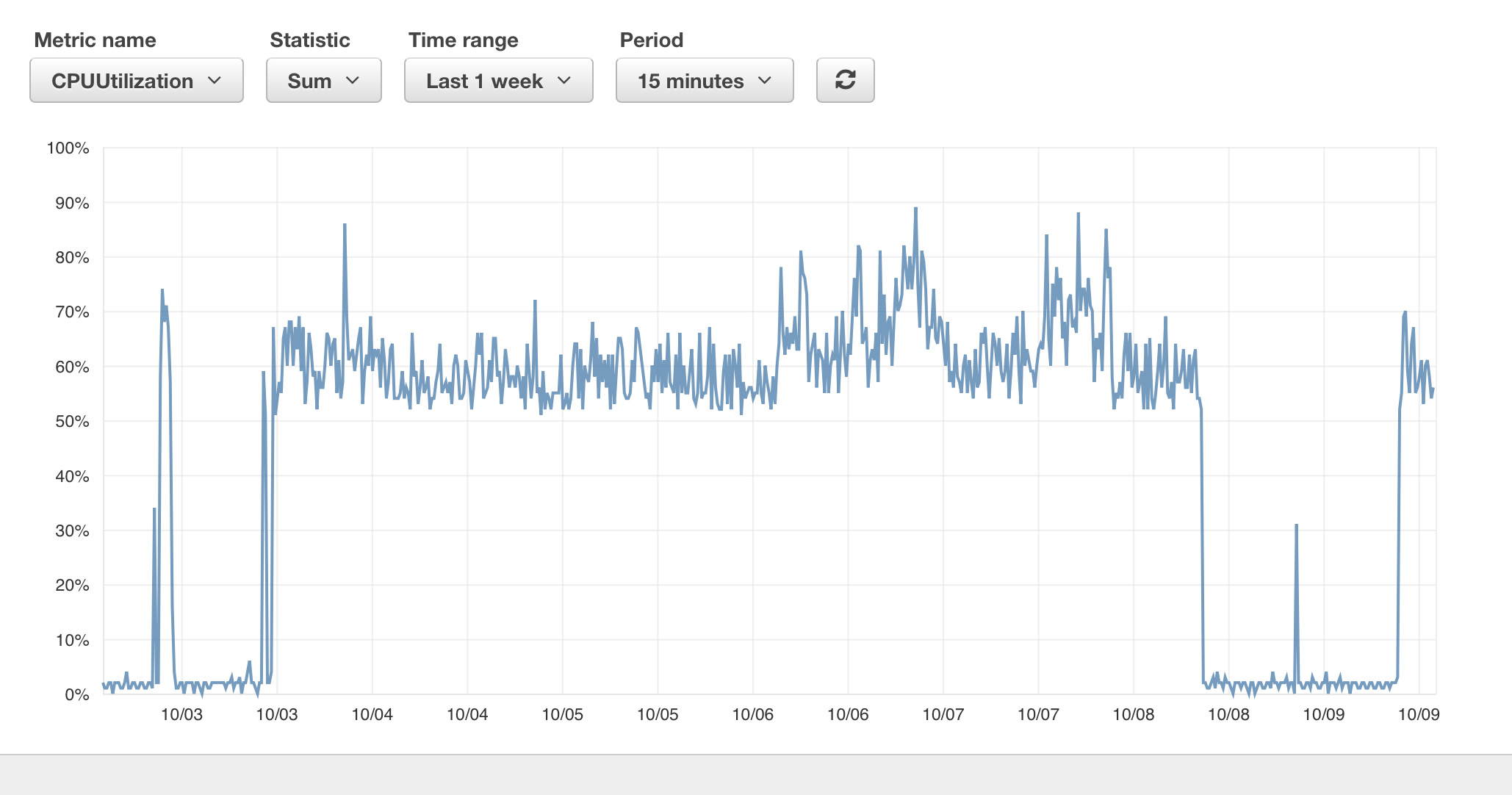
We have an AWS Elasticsearch Service cluster that we (are trying to) continually push data to. To me, it isn't a crazy amount of data, maybe 12M documents a day. We use the bulk endpoint to push through ~500 documents at a time.
We have periods where we are able to push about 1 million documents through in an hour. This runs successfully for some period of time, sometimes days. Then, it stops with nothing changing on our end. IOPS go way down, throughput goes way down, and we no longer can make any bulk requests to the cluster. AWS Elasticsearch Service does not allow a timeout value larger than 60s, and essentially all of our bulk pushes begin to receive a 504 transport error once this drop-off occur.
All of our metrics that we can see seem fine.
Stats about the cluster/index:
ES 5.1
~350 GB free
~60 GB used
5 r4.xlarge nodes
1000 Provisioned IOPS
index has 5 shards
pushing to the cluster using elasticsearch-py in AWS Lambda functions
Any help/guidance would be greatly appreciated. I made a post in the AWS forums, but no one has replied.
This is the link to it:
https://forums.aws.amazon.com/message.jspa?messageID=806068
Thanks