Hi,
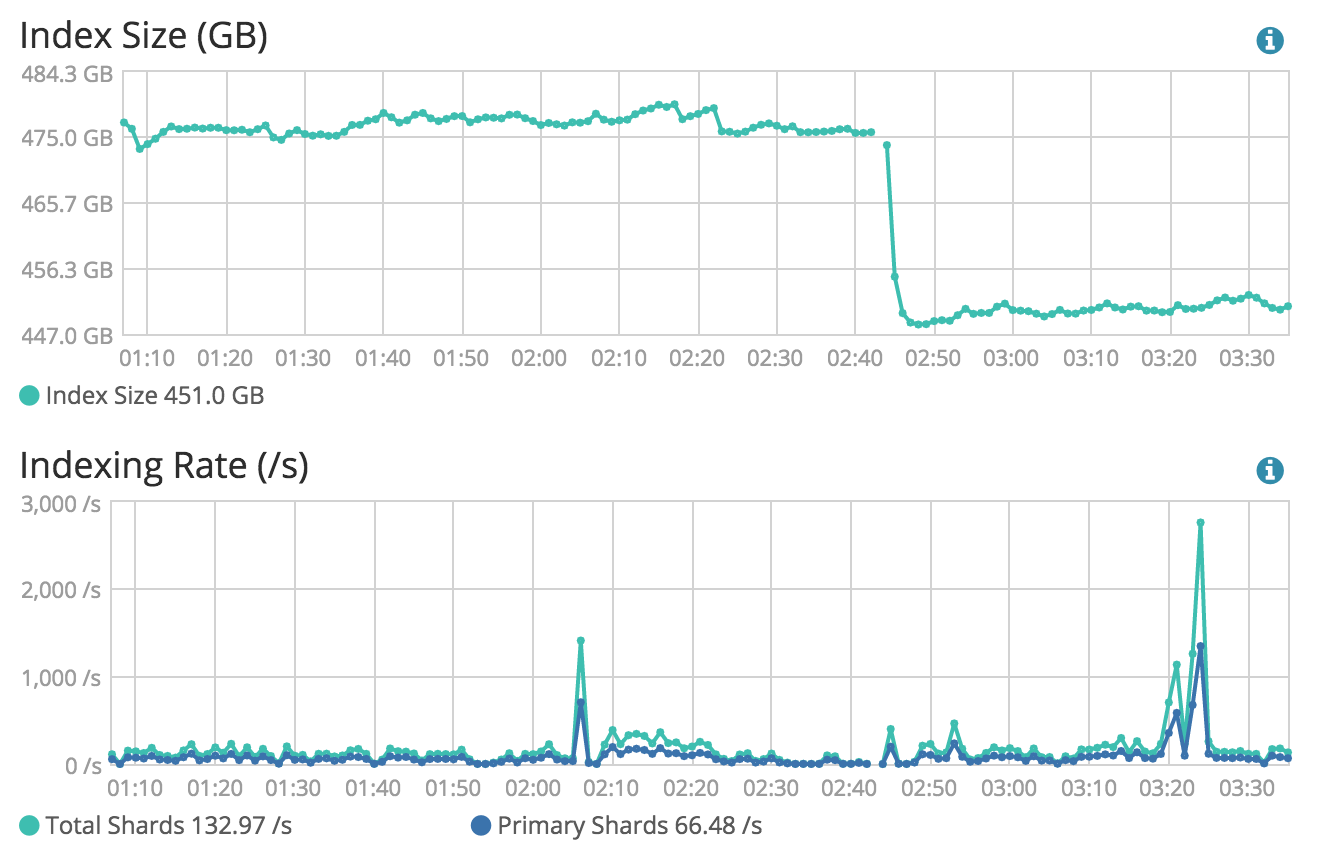
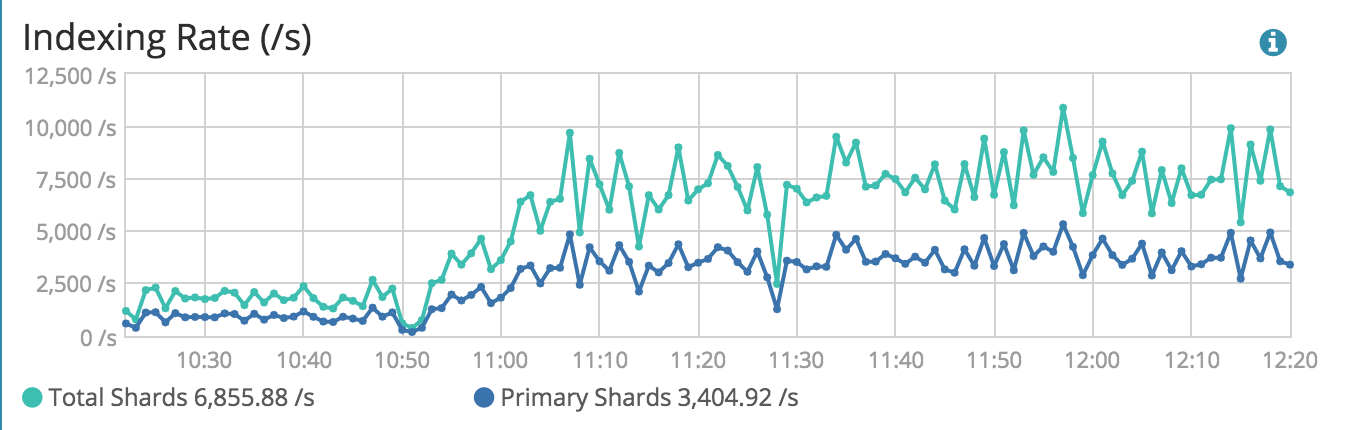
We have a 5.2.2 cluster and we have noticed that usually once or twice a day we will see a large merge happen 5-10GB that leads to a CPU spike across all our nodes and the the cluster being unreachable. By unreachable I mean any request from our app returns a 503 from ES during the time the merge is happening. Below is an example of one such merge that just happened. We do a lot of updating documents so we expect there to be a fair amount of merging especially to expunge deletes but the frequency at which the merges are leading to 503s for our users is too high.
Index Size Drop indicative of a large Merge

Average Indexing over a 2 hour period including the large merge
Our hardward specs are:
- 3x Client Nodes with 30 Gb of RAM
- 3x Master Nodes with 16 Gb of RAM
- 18x Data Nodes with 60 Gb of RAM
- All of these EC2 instances have SSD-backed instance storage. All of our ES configs use 50% of the RAM on each of the above instances for ES. The data nodes do not go over the recommended 31.5Gb RAM limit.
Merge policy settings and refresh rate:
"merge": {
"policy": {
"floor_segment": "100mb",
"reclaim_deletes_weight": "2",
"max_merged_segment": "5gb"
}
},
"refresh_interval": "30s"
We have tried slightly longer refresh rates of 1m but we still see the merge issues even with those. Besides the merge issues the cluster runs great, heap is consistent, nothing else seems out of the ordinary. On ES 2.3 we would see large merges cause 503's maybe once a month but since upgrading to 5.2.2 it is happening much more frequently.
Is there a way we can tweak our settings to prevent the large merges from causing 503's?
Thanks!