Hi guys,
we are experiencing nodes lefting and joining the cluster intermittently and sometimes our elasticsearch cluster is taking too long to load the following pages (required by kopf):
/_stats/docs,store
/_nodes/stats/jvm,fs,os,process
/_nodes/_all/os,jvm
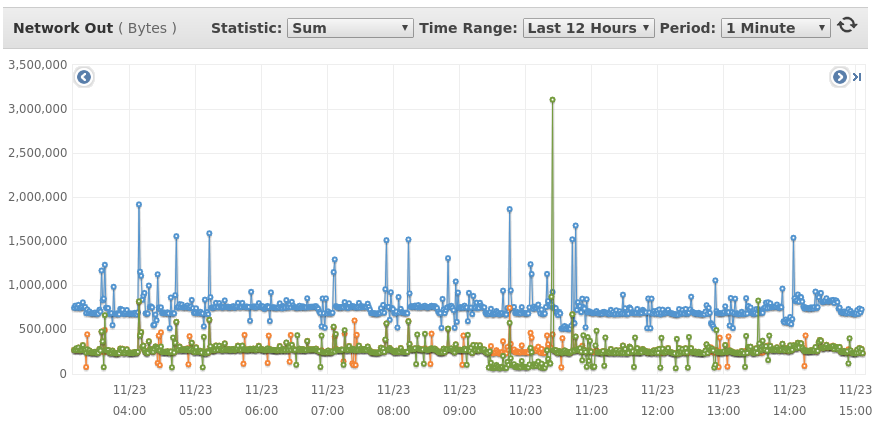
I was suspecting about master nodes working under heavy load but it's seems not the case (the cpu utilization is under 10% and the network usage is low):
We are running 3 master nodes (m3.medium) and 16 data nodes (c4.4xlarge). Do you have any clues about what is causing this behavior?
All those stats seem to need to gather information from all the nodes in the cluster. What does CPU and GC look like on the non-master nodes?
Thanks for your fast reply, the output from /_nodes/stats/jvm is here (some fields removed for brevity): https://gist.github.com/wedneyyuri/233af79d4082fa053245604499b22c96
I'm running Elasticsearch 2.4 on Ubuntu 16. The configuration is:
cluster.routing.allocation.awareness.attributes: aws_availability_zone
plugin.mandatory: cloud-aws
bootstrap.mlockall: true
transport.tcp.compress: true
indices.queries.cache.size: 30%
indices.requests.cache.size: 20%
indices.memory.index_buffer_size: 20%
index.requests.cache.enable: true
index.unassigned.node_left.delayed_timeout: 2m
index.refresh_interval: 10m
action.get.realtime: false
cloud.node.auto_attributes: true
discovery:
type: ec2
ec2:
ping_timeout: 30s
tag.cluster: ${CLUSTER_NAME}
host_type: private_dns
discovery.zen:
minimum_master_nodes: ${SPLIT_BRAIN_NODES}
ping_timeout: 30s
ping:
multicast.enabled: false
unicast.hosts: []
script.engine.groovy.inline.search: on
script.inline: on
index.similarity.default.type: BM25