Hi,
we use LS 6.7.1 on RHEL 7.6 (installed with rpm). There we have about 20 pipelines running on 2 LS instances on different servers with ~3-4k syslog events / second. We use the central pipeline management feature of Kibana. Since a few days, all events from one of the pipelines with about 50 e/s are disappearing directly after the tcp input plugin. The events get ingested into the pipeline (verified by tcpdump) but they don't get processed by the filters and outputs. Also, the CPU utilization of the Logstash instance is maxed out. The LS server has 12 GB RAM and 6 vCPUs with 6GB Heap allocated to Logstash.
The logfile does not show any errors regarding this pipeline (ID: "_10000-nw-syslogs_p001"):
Logstash monitoring shows no hints about the problem, except that the persistent queue events are quite high:


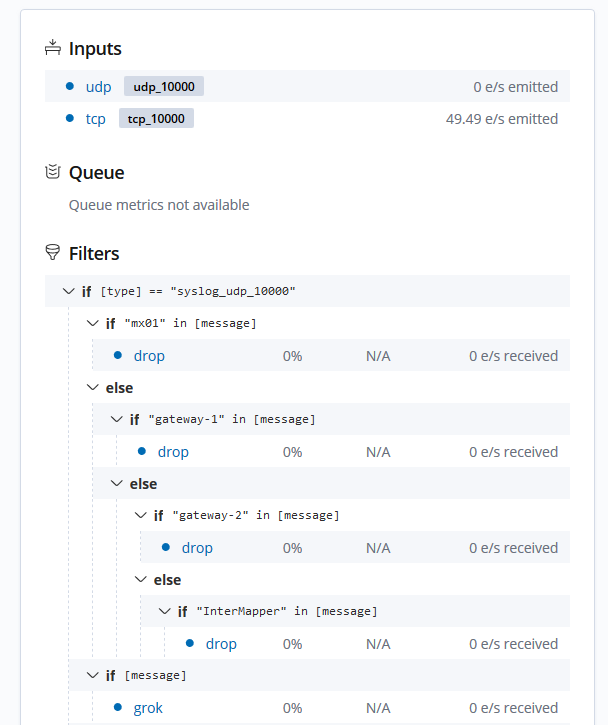
The pipeline definition can be found here.
Any idea?