Our cluster is operating pretty well .. but we noticed that our warm data nodes are under some intense JVM pressure. This could be self inflicted with our mappings and data size, but I am looking for a way to confirm this.
First, our cluster looks like this:
-
hotingestion nodes:40 x i3.2xl (8vcpu, 61gb ram, 30gb dedicated to ES) -
warmnodes:10 x d2.2xl (8vcpu, 61gb ram, 30gb dedicated to ES) -
masternodes :3 x r3.xlarge
We have three index patterns today.. aws, syslog and cloudtrail logs. Each index runs in a rolling mode based on index size. So..
-
logs-aws-xxxxxx: 16 shards @ 1x replication, roll @ 512gb -
logs-syslog-xxxxxx: 32 shards @ 1x replication, roll @ 1024gb -
logs-cloudtrail-xxxxxx: 2 shards @ 1x replication, roll @ 100gb
Finally, we ingest around 2 billion events a day.. ~1.1b into the syslog index, ~900m into the aws index, and a few million into the cloudtrail indices.
On our hot ingestion nodes, we see a pretty good memory pattern.. up and down plenty, but never really breaking ~80%. Here are all the nodes:

Here's one node singled out:

Unfortunately, our warm nodes are doing much worse:


Finally, here is the GC log on a single warm node:
{"timeMillis":1524514971934,"thread":"elasticsearch[XXX][scheduler][T#1]","level":"INFO","loggerName":"org.elasticsearch.monitor.jvm.JvmGcMonitorService","marker":{"name":"[XXX] "},"message":"[gc][132234] overhead, spent [448ms] collecting in the last [1s]","endOfBatch":false,"loggerFqcn":"org.apache.logging.log4j.spi.AbstractLogger","threadId":21,"threadPriority":5,"source":{"class":"org.elasticsearch.monitor.jvm.JvmGcMonitorService","method":"logGcOverhead","file":"JvmGcMonitorService.java","line":321}}
{"timeMillis":1524514974147,"thread":"elasticsearch[XXX][scheduler][T#1]","level":"INFO","loggerName":"org.elasticsearch.monitor.jvm.JvmGcMonitorService","marker":{"name":"[XXX] "},"message":"[gc][132236] overhead, spent [437ms] collecting in the last [1.2s]","endOfBatch":false,"loggerFqcn":"org.apache.logging.log4j.spi.AbstractLogger","threadId":21,"threadPriority":5,"source":{"class":"org.elasticsearch.monitor.jvm.JvmGcMonitorService","method":"logGcOverhead","file":"JvmGcMonitorService.java","line":321}}
{"timeMillis":1524514975318,"thread":"elasticsearch[XXX][scheduler][T#1]","level":"WARN","loggerName":"org.elasticsearch.monitor.jvm.JvmGcMonitorService","marker":{"name":"[XXX] "},"message":"[gc][132237] overhead, spent [588ms] collecting in the last [1.1s]","endOfBatch":false,"loggerFqcn":"org.apache.logging.log4j.spi.AbstractLogger","threadId":21,"threadPriority":5,"source":{"class":"org.elasticsearch.monitor.jvm.JvmGcMonitorService","method":"logGcOverhead","file":"JvmGcMonitorService.java","line":316}}
{"timeMillis":1524514978319,"thread":"elasticsearch[XXX][scheduler][T#1]","level":"WARN","loggerName":"org.elasticsearch.monitor.jvm.JvmGcMonitorService","marker":{"name":"[XXX] "},"message":"[gc][132240] overhead, spent [580ms] collecting in the last [1s]","endOfBatch":false,"loggerFqcn":"org.apache.logging.log4j.spi.AbstractLogger","threadId":21,"threadPriority":5,"source":{"class":"org.elasticsearch.monitor.jvm.JvmGcMonitorService","method":"logGcOverhead","file":"JvmGcMonitorService.java","line":316}}
{"timeMillis":1524514979656,"thread":"elasticsearch[XXX][scheduler][T#1]","level":"WARN","loggerName":"org.elasticsearch.monitor.jvm.JvmGcMonitorService","marker":{"name":"[XXX] "},"message":"[gc][132241] overhead, spent [766ms] collecting in the last [1.3s]","endOfBatch":false,"loggerFqcn":"org.apache.logging.log4j.spi.AbstractLogger","threadId":21,"threadPriority":5,"source":{"class":"org.elasticsearch.monitor.jvm.JvmGcMonitorService","method":"logGcOverhead","file":"JvmGcMonitorService.java","line":316}}
{"timeMillis":1524514982657,"thread":"elasticsearch[XXX][scheduler][T#1]","level":"WARN","loggerName":"org.elasticsearch.monitor.jvm.JvmGcMonitorService","marker":{"name":"[XXX] "},"message":"[gc][132244] overhead, spent [669ms] collecting in the last [1s]","endOfBatch":false,"loggerFqcn":"org.apache.logging.log4j.spi.AbstractLogger","threadId":21,"threadPriority":5,"source":{"class":"org.elasticsearch.monitor.jvm.JvmGcMonitorService","method":"logGcOverhead","file":"JvmGcMonitorService.java","line":316}}
{"timeMillis":1524514984012,"thread":"elasticsearch[XXX][scheduler][T#1]","level":"WARN","loggerName":"org.elasticsearch.monitor.jvm.JvmGcMonitorService","marker":{"name":"[XXX] "},"message":"[gc][132245] overhead, spent [793ms] collecting in the last [1.3s]","endOfBatch":false,"loggerFqcn":"org.apache.logging.log4j.spi.AbstractLogger","threadId":21,"threadPriority":5,"source":{"class":"org.elasticsearch.monitor.jvm.JvmGcMonitorService","method":"logGcOverhead","file":"JvmGcMonitorService.java","line":316}}
It looks to me like the issue has to do with our data patterns - we index, analyze and store keyword fields for basically everything. Looking at some of the metrics, it looks like we're using ~120GB or so (across 10 nodes, right?) for terms/etc:

The same data on the hot nodes (40 nodes) is far lower..
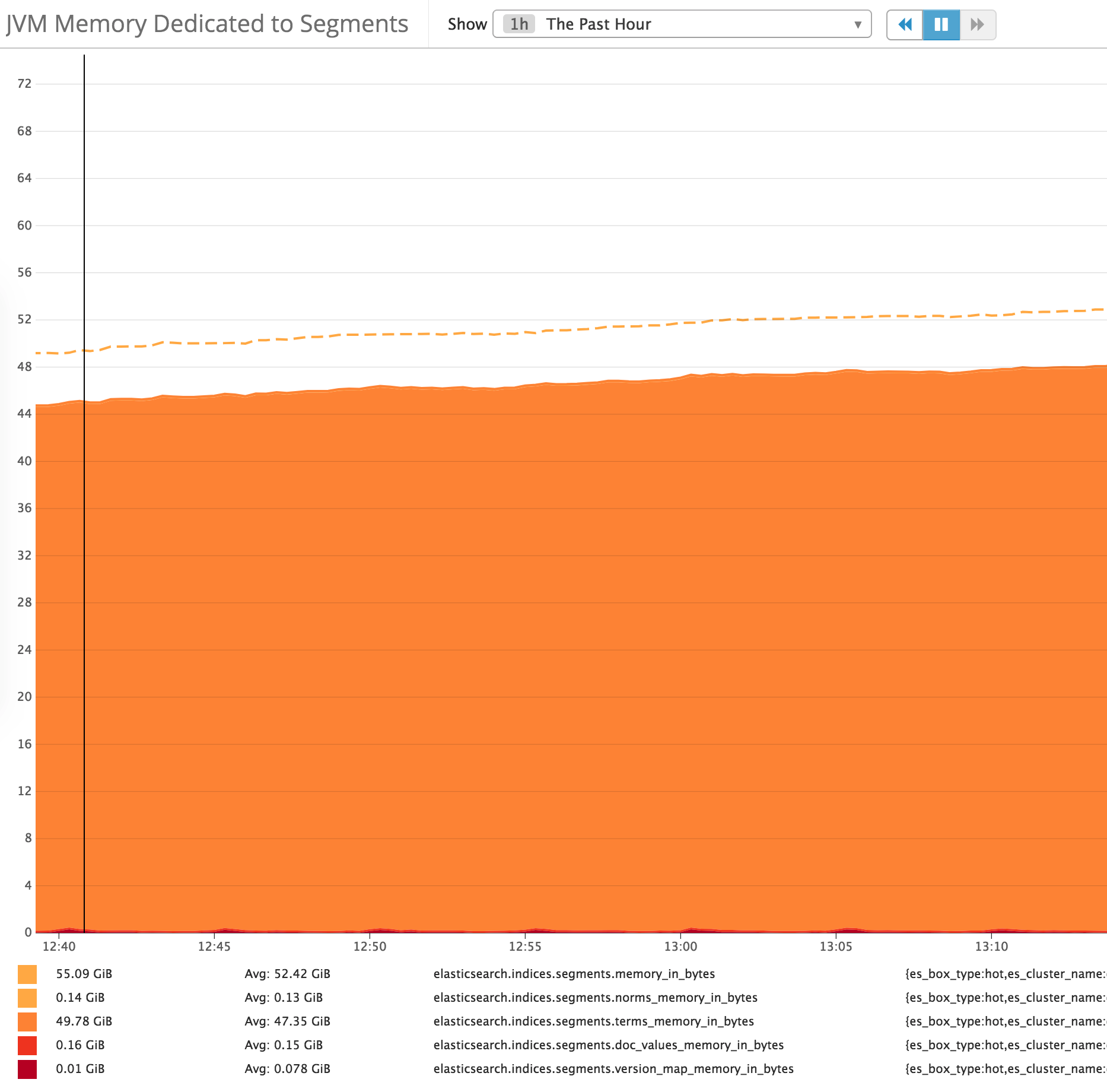
So obviously we are storing less data on each hot node, and prioritizing CPU/IO for them.. but on our warm nodes it seems like something strange is going on here. We have 10 nodes, so thats ~300GB or so in HEAP memory. Only ~40% of that is accounted for in these graphs.. so whats using the other 50%?
Are there things we can do to tune our warm nodes differently? Let them rely more heavily on FS-cache and reading from disk when necessary, keeping less terms/etc in memory?