I use Elasticsearch and Kibana, I submit my data with the bulk API in vb.net program.
I did not make any special configuration in elastic search.
here is the content of the file elasticsearch.yml :
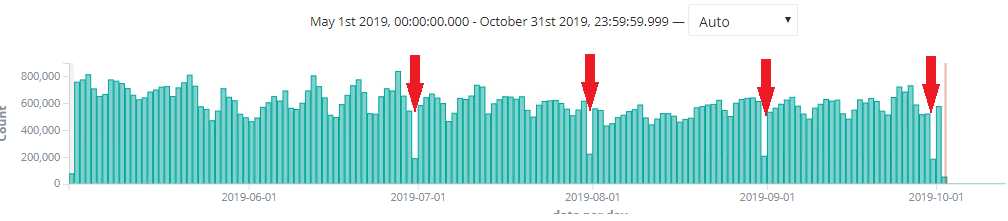
On average, I send 600 000 lines a day.
In recent months I have noticed that every month I have a loss of data periodically instead of 600 miles lines on average, I have :
30-06-2019 : 188,626
31-07-2019 : 221,839
31-08-2019 : 206,808
30-09-2019 : 184,473
as shown in this screenshot
Do you analyse each bulk response to verify there were no errors and retry if there are? What version of Elasticsearch are you using? How large is your cluster and what does your Elasticsearch.yml file look like?
Hello Christian_Dahlqvist,
Thank you for your reply.
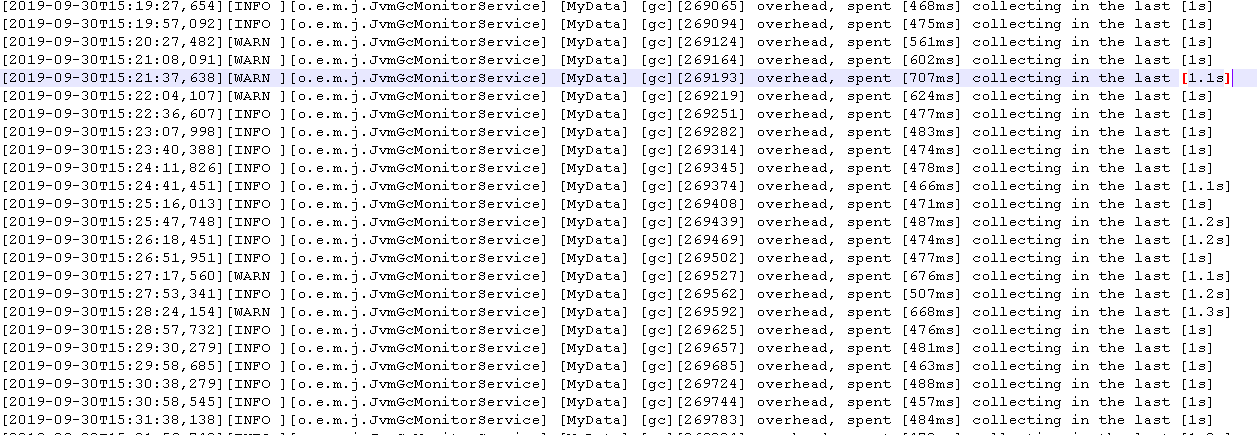
1- Yes I analyzed the bulk answers, no problem, the answer is like: http://localhost:9200//_bulk
{"took":380, "errors":false,
4- Yes, as I have already said, my client program sends, on average 600 thousand lines per day, even in the days when there is a problem he sent the data with the same frequency .
Are you checking the responses for your bulk requests in your application? The cluster might be rejecting requests due to load, or fail certain requests, which means that you will have to retry those. In particular are you checking whether errors : false in the bulk response?
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.