okay so i need help. i am currently working on a project where millions of documents have to be displayed. Currently, there are 50 documents on each page, and there are 200 pages, totaling 10,000 documents. however, i want the user to click next page or the arrow and it allows them to go to page 201, 202, 300, 400, etc, until it reaches the end of the documents. yes I know it is a lot, but it is required.
i am currently using Elastic Search for this. as well as Python and javascript. however, what i have right now is not working. i read Elasticsearch documentation and it says that i need to use the search_after parameter along with the point in time. however, i keep getting errors with what i have. these error messages are making me crazy. below is what I currently have so far.
@blueprint.route("/browse-all", methods=["GET"])
def browse_all():
"""
This view function handles GET requests for the Browse All page.
A query is made for the initial page of certificates shown.
:return: Template for the browse all page and a list of certificates to display.
Redirect to public.view_certificate if only one certificate is returned.
"""
# Get default year range/values
try:
cached_year_range = get_year_range()
if cached_year_range and cached_year_range.year_min and cached_year_range.year_max:
default_year_range_value = f"{cached_year_range.year_min} - {cached_year_range.year_max}"
else:
raise ValueError("Invalid year range")
except Exception as e:
current_app.logger.error(f"Error getting year range: {str(e)}")
default_year_range_value = "1855 - 1949" # Fallback range
form = BrowseAllForm()
page = request.args.get('page', 1, type=int)
page_size = 50
# Set up variables for search
q_list = []
for key, value in request.args.items():
if key != 'page' and value:
if key == "year_range":
year_range = [int(year) for year in value.split() if year.isdigit()]
if len(year_range) == 2:
q_list.append(Q("range", year={"gte": year_range[0], "lte": year_range[1]}))
elif key in ["first_name", "last_name"]:
q_list.append(Q("multi_match", query=value.capitalize(), fields=[key, f"spouse_{key}"]))
elif key == "certificate_type" and value == "marriage":
q_list.append(Q("terms", cert_type=[certificate_types.MARRIAGE, certificate_types.MARRIAGE_LICENSE]))
else:
q_list.append(Q("match", **{key: value}))
q = Q("bool", must=q_list) if q_list else Q("match_all")
# Define the sort order
sort_order = [{"_doc": "asc"}]
# Create a new PIT for each request
pit = es.open_point_in_time(index="certificates", keep_alive="1m")
pit_id = pit['id']
# Get search_after from request arguments
search_after = request.args.get('search_after')
if search_after:
search_after = search_after.split(',')
# Construct the search body
body = {
"size": page_size,
"query": q.to_dict(),
"sort": sort_order,
"pit": {
"id": pit_id,
"keep_alive": "1m"
}
}
if search_after and page > 1:
body["search_after"] = search_after
# Perform the search
try:
response = es.search(body=body)
except Exception as e:
current_app.logger.error(f"Elasticsearch error: {str(e)}")
return render_template("public/error.html", error_message="An error occurred while searching. Please try again.")
# Get the total count
count = response["hits"]["total"]["value"]
# If only one certificate is returned, go directly to the view certificate page
if count == 1:
es.close_point_in_time(id=pit_id)
return redirect(url_for("public.view_certificate", certificate_id=response["hits"]["hits"][0]["_id"]))
# Process hits to include image URLs
processed_hits = []
for hit in response['hits']['hits']:
processed_hit = hit['_source']
processed_hit['_id'] = hit['_id']
if 'image_url' not in processed_hit:
processed_hit['image_url'] = url_for('static', filename='images/placeholder.png')
processed_hits.append(processed_hit)
# Set form data from previous form submissions
for field in form:
if field.name in request.args:
field.data = request.args[field.name]
# Simplified remove_filters logic
remove_filters = {}
for key, value in request.args.items():
if key not in ['page', 'search_after'] and value:
if not (key == "year_range" and value == default_year_range_value):
label = value
if key == "certificate_type":
label = certificate_types.CERTIFICATE_TYPE_VALUES.get(value, value)
elif key == "county":
label = counties.COUNTY_VALUES.get(value, value)
args_without_filter = request.args.copy()
args_without_filter.pop(key)
new_url = url_for('public.browse_all', **args_without_filter)
remove_filters[key] = (label, new_url)
# Define pagination
pagination = Pagination(page=page, total=count, per_page=page_size, css_framework="bootstrap4")
next_page = page + 1 if len(response['hits']['hits']) == page_size else None
# Prepare next_args for the next page URL
next_args = request.args.copy()
if next_page:
next_args['page'] = next_page
if response['hits']['hits']:
next_args['search_after'] = ','.join(map(str, response['hits']['hits'][-1]['sort']))
else:
next_args.pop('page', None)
next_args.pop('search_after', None)
# Close the PIT
es.close_point_in_time(id=pit_id)
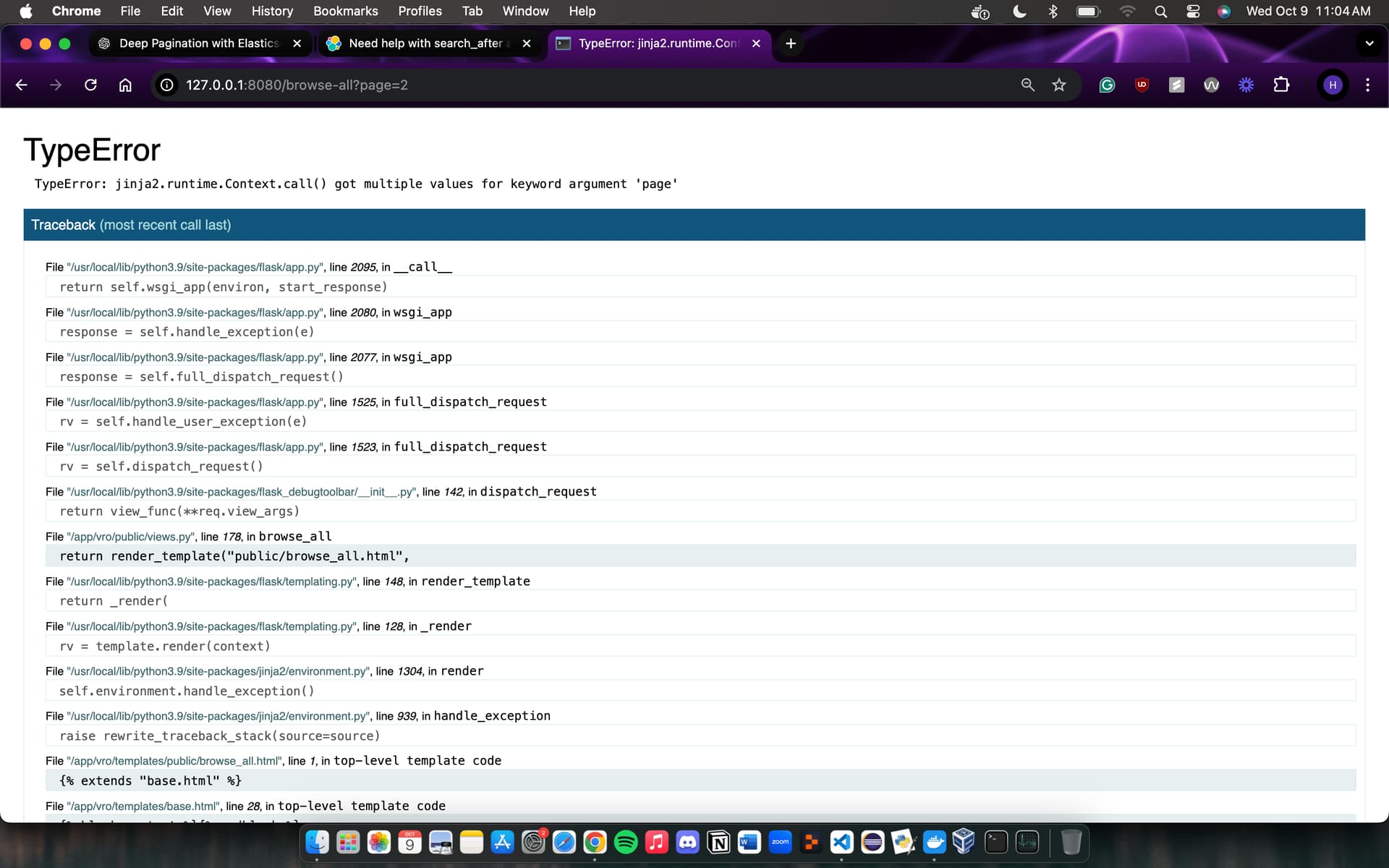
return render_template(
"public/browse_all.html",
form=form,
certificates=processed_hits,
pagination=pagination,
remove_filters=remove_filters,
num_results=count,
next_page=next_page,
next_args=next_args,
certificate_types=certificate_types,
counties=counties,
min=min,
default_year_range_value=default_year_range_value
)