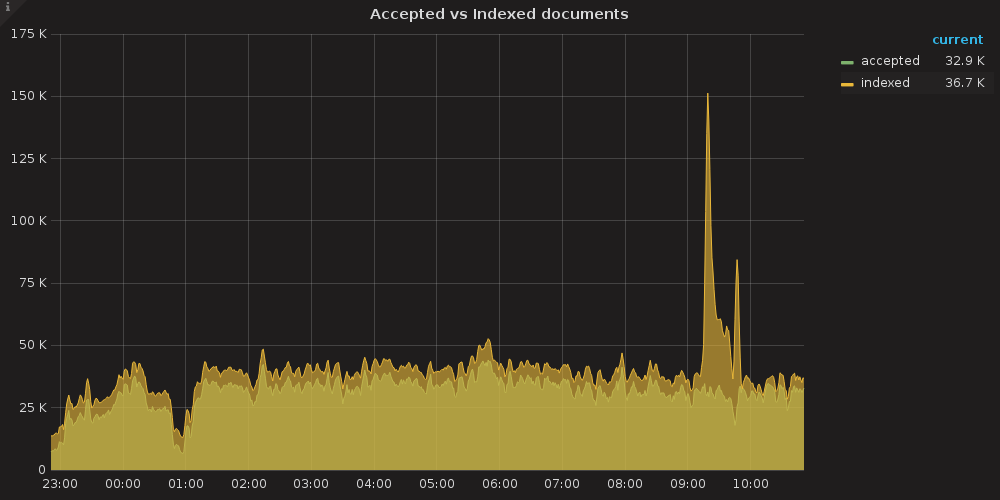
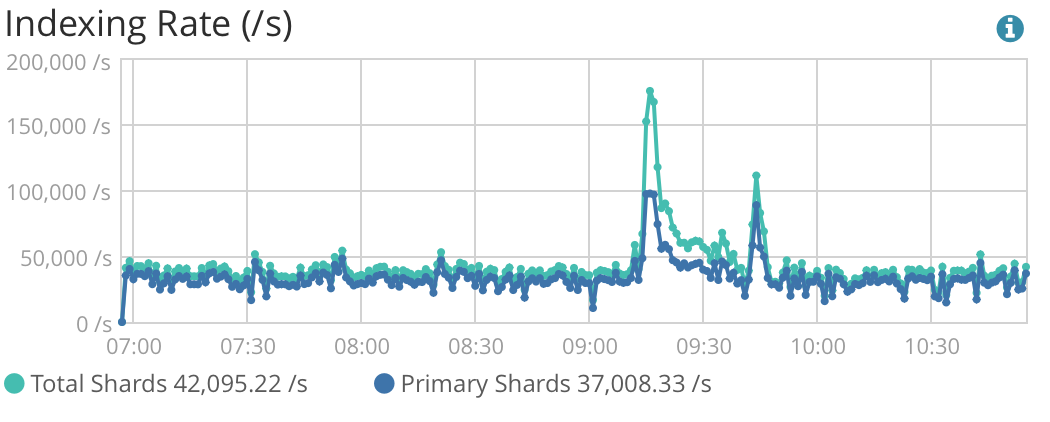
We have a staging server with continuous indexing flow of around 40k req/sec. The cluster of 15 nodes can work for 2-12 hours, and then we see spikes in indexing, while there is no increase in incoming flow.
I can see that during this period, we have a bunch of bulk requests, this can be a reason or a cause of something that happening to the cluster.
The question is - how can I debug what is going on with the cluster? I don't see anything special in the logs. We increased bulk queue size to 3000, Elastic version is 5.3.0, configuration file:
why did you change the bulk size? Have you seen indexing issues? Requests timing out?
So far, this data only seems to tell, that there has been an increased indexing volume, but I do not see any problems arising.
How do you know that there is no spike in incoming data, if you know that bulk requests happened? Do you have other monitoring to know that there is no spike and that no other component is indexing a lot of data?
Do you see those number of documents in your datasets or does it just vanish? You could try to do a _count operation during the same time to compare that with the number of documents being found (even though this is not the full truth due to deleted documents, but it might be a start).
Our processing pipeline is following:
fluent bit (on client side) -> fluentd (on servers side) -> elastic search ( server side).
We do have monitoring on incoming messages on fluentd side, as well as outgoing counter for client side.
I have suspect that it may be related to inaccessible node due to network issues. I have seen several messages like this:
[2017-12-02T20:45:21,268][WARN ][o.e.c.NodeConnectionsService] [elasticsearch-ca-ovh-08] failed to connect to node {elasticsearch-ca-ovh-18}{Bw9yXDrKSlW2tNgrseOpKg}{bzuGHbySTJSVSasLnVUWgg}{144.217.68.127}{144.217.68.127:9300} (tried [1] times)
org.elasticsearch.transport.ConnectTransportException: [elasticsearch-ca-ovh-18][144.217.68.127:9300] connect_timeout[30s]
What is weird, is that the node with network issues is not related to data processing. It is basically kibana proxy. Why does fail on non-data/master/indexing node cause overall cluster reindexing?
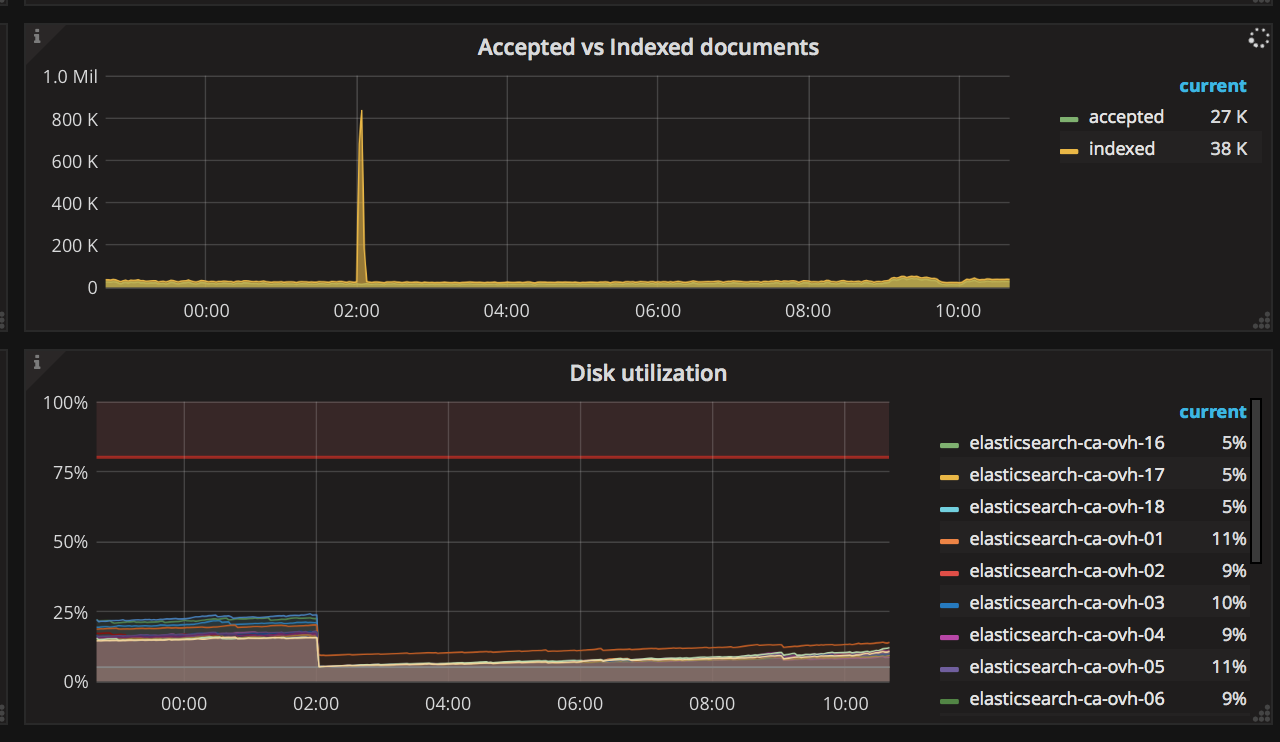
What else I have noticed, is that we have spikes during retention period, when we start dropping some indices. Is there any way to prevent reindexing after the index drops, as we have huge indices and it cause quite some overload to the cluster.
I mean that as soon as we have a retention policy applied (we drop indices with date older than some date), we have huge spike in indexing, as you can see in screenshot above.
Which happens at around 2am, in that particular example. I would like to avoid that huge spikes, or they are normal?
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.