I tried to fix the issue by following the suggested guide. I scaled our deployment up by increasing the availability zones (from 1 to 2), like the guide suggested. When I did this, the health warning seemed to be resolved.
However, when I scale back down, the exact health warning returns. Should I give it some more time to resolve? I'm not sure how to fix this. I'm quite new, so any help is appreciated. If you need some more logging information, feel free to ask.
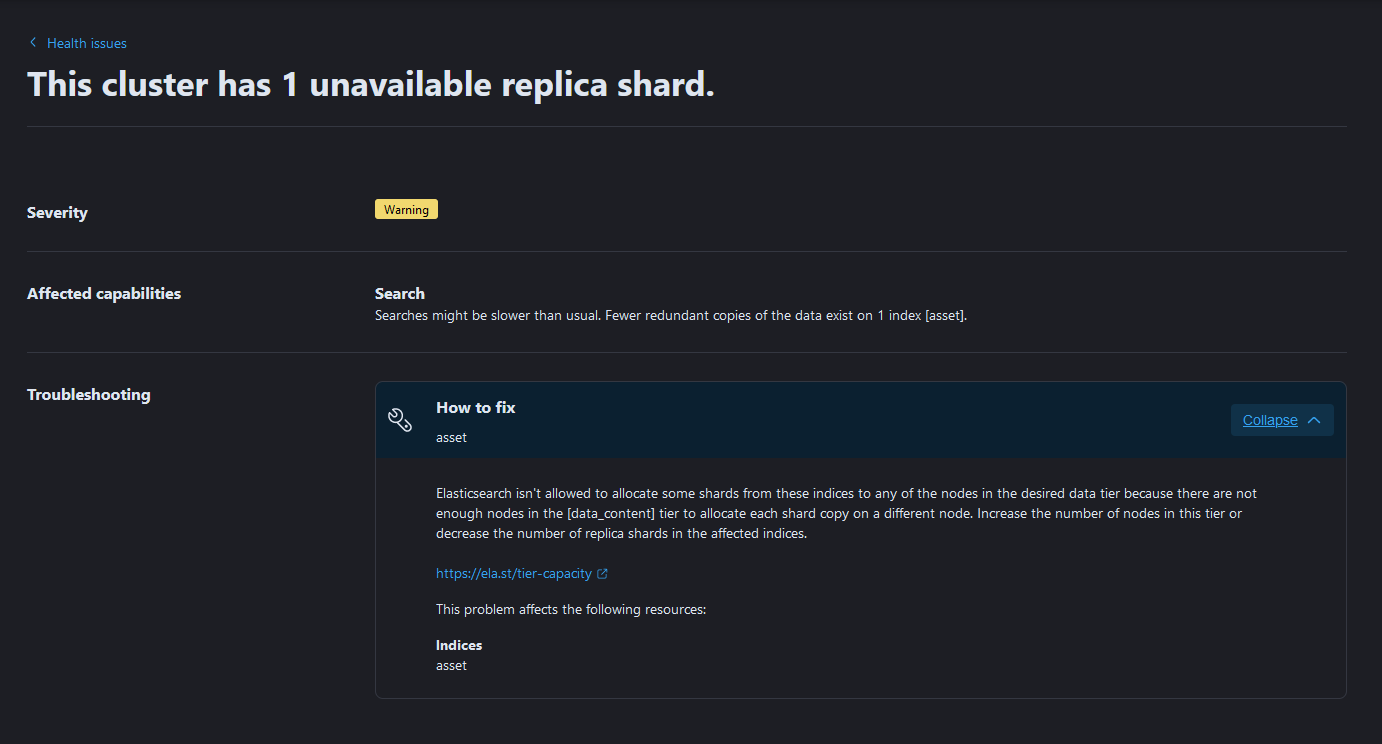
I think you might getting the error because Elasticsearch is trying to assign the replica shard to another instance.
You can set that to 0 I think on that index. Then you'll have the primary shard only. Elasticsearch then won't try and place the replica on another instance. Checking here can give you information on your shards is: cat shards API | Elasticsearch Guide [8.6] | Elastic
What do you mean with "You can set that to 0 I think on that index"? Could you please elaborate on this? I already tried to decrease the number of replicas to 0, however this wasn't a success.
Elasticsearch wouldn't assign the replica shard to the same instance as the primary shard. It's recommended to have 1 primary and 1 replica. The replica is a redundant shard so if the primary fails the replica is promoted to a primary and Elasticsearch creates a new replica.
Do you have a few instances on your cluster, have index lifecycle management policy that might be using tiering? Also, if you were to check the assets index from the dev console:
GET _cat/shards/assets*
It can let you know which node the replica is on at the end of the output and the shard status.
Will you be able to provide the output of the command: GET _cluster/allocation/explain ? This will provide more insight as to why the shard is not being assigned to any node.
It seems like you have a single node cluster, however, your index setting requires 1 primary and 1 replica shard to be initialized. This will certainly cause issues since primary and replica shards cannot reside on same node.
So, you have, for now, 2 options:
Scale down the indices and set number_of_replicas=0
Add atleast another node so both primary and replica shards can be allocated.
Please note, having 2 nodes cluster may lead to split-brain issue while electing the master node, hence its recommended to have odd numbered node cluster.
This is not the case in recent versions. The reason 3 master eligible nodes are recommended is that master election requires a strict majority of master eligible nodes to agree. If you have 3 nodes a master can be elected even if one node is unavailable. If you instead onlty have 2 nodes, a master can only be elected if both nodes are available and the cluster will not fully function if one node is missing.
@Christian_Dahlqvist what you mentioned is about node quorum. When it comes to master node election, let's say your have a 2 node cluster and each node vote for itself to become master, you have split-brain still. In this case, you may configure one of the node for only voting while other can have master role (by default).
No, that is incorrect. If they can communicate they will negotiate until one is elected. If they can not communicate they will not be able to reach consensus and the cluster will be split.
Just to reinforce what Christian is saying, the statement above is indeed false. It hasn't really ever been true (unless you misconfigure something) and since 7.0 it hasn't even been possible to misconfigure things so badly that there is a risk of a split-brain. All sizes of Elasticsearch cluster are resistant to split brain situations no matter how they are configured.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.