I am doing log analysis using Filebeat (1.2) -> logstash(2.3) -> Elasticsearch (2.3)
I have 4 filebeat instances, 4 logstash instances (6 cores each, 8G RAM) , and Elasticsearch cluster (8 cores, 64G RAM) of 2 nodes
When the traffic was pretty high >6000 msg/sec, 10% to 20% of messges are lost.
The errors in elasticsearch log shows:
[2016-07-10 01:47:28,790][DEBUG][action.admin.cluster.node.stats] [Melasticsearch] failed to execute on node [e8rsvmGRReWzFOCem4Fxeg]
RemoteTransportException[[Melasticsearch][10.100.16.13:9300][cluster:monitor/nodes/stats[n]]]; nested: AlreadyClosedException[this IndexReader is closed];
Caused by: org.apache.lucene.store.AlreadyClosedException: this IndexReader is closed
at org.apache.lucene.index.IndexReader.ensureOpen(IndexReader.java:274)
at org.apache.lucene.index.CompositeReader.getContext(CompositeReader.java:101)
at org.apache.lucene.index.CompositeReader.getContext(CompositeReader.java:55)
at org.apache.lucene.index.IndexReader.leaves(IndexReader.java:438)
at org.elasticsearch.search.suggest.completion.Completion090PostingsFormat.completionStats(Completion090PostingsFormat.java:330)
at org.elasticsearch.index.shard.IndexShard.completionStats(IndexShard.java:765)
at org.elasticsearch.action.admin.indices.stats.CommonStats.(CommonStats.java:164)
at org.elasticsearch.indices.IndicesService.stats(IndicesService.java:253)
at org.elasticsearch.node.service.NodeService.stats(NodeService.java:158)
at org.elasticsearch.action.admin.cluster.node.stats.TransportNodesStatsAction.nodeOperation(TransportNodesStatsAction.java:82)
at org.elasticsearch.action.admin.cluster.node.stats.TransportNodesStatsAction.nodeOperation(TransportNodesStatsAction.java:44)
at org.elasticsearch.action.support.nodes.TransportNodesAction.nodeOperation(TransportNodesAction.java:92)
at org.elasticsearch.action.support.nodes.TransportNodesAction$NodeTransportHandler.messageReceived(TransportNodesAction.java:230)
at org.elasticsearch.action.support.nodes.TransportNodesAction$NodeTransportHandler.messageReceived(TransportNodesAction.java:226)
at org.elasticsearch.transport.RequestHandlerRegistry.processMessageReceived(RequestHandlerRegistry.java:75)
at org.elasticsearch.transport.TransportService$4.doRun(TransportService.java:376)
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:37)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
[2016-07-10 01:47:28,791][ERROR][marvel.agent.collector.node] [Melasticsearch] collector [node-stats-collector] - failed collecting data
java.lang.ArrayIndexOutOfBoundsException
Logstash error log shows error:
Beats input: The circuit breaker has detected a slowdown or stall in the pipeline, the input is closing the current connection and rejecting new connection until the pipeline recover. {:exception=>LogStash::Inputs::BeatsSupport::CircuitBreaker::HalfOpenBreaker, :level=>:warn}
CircuitBreaker::rescuing exceptions {:name=>"Beats input", :exception=>LogStash::Inputs::Beats::InsertingToQueueTakeTooLong, :level=>:warn}
This is the marvel screen catch for the 2 elasticsearch nodes

In Newrelic monitor, logstash instance:

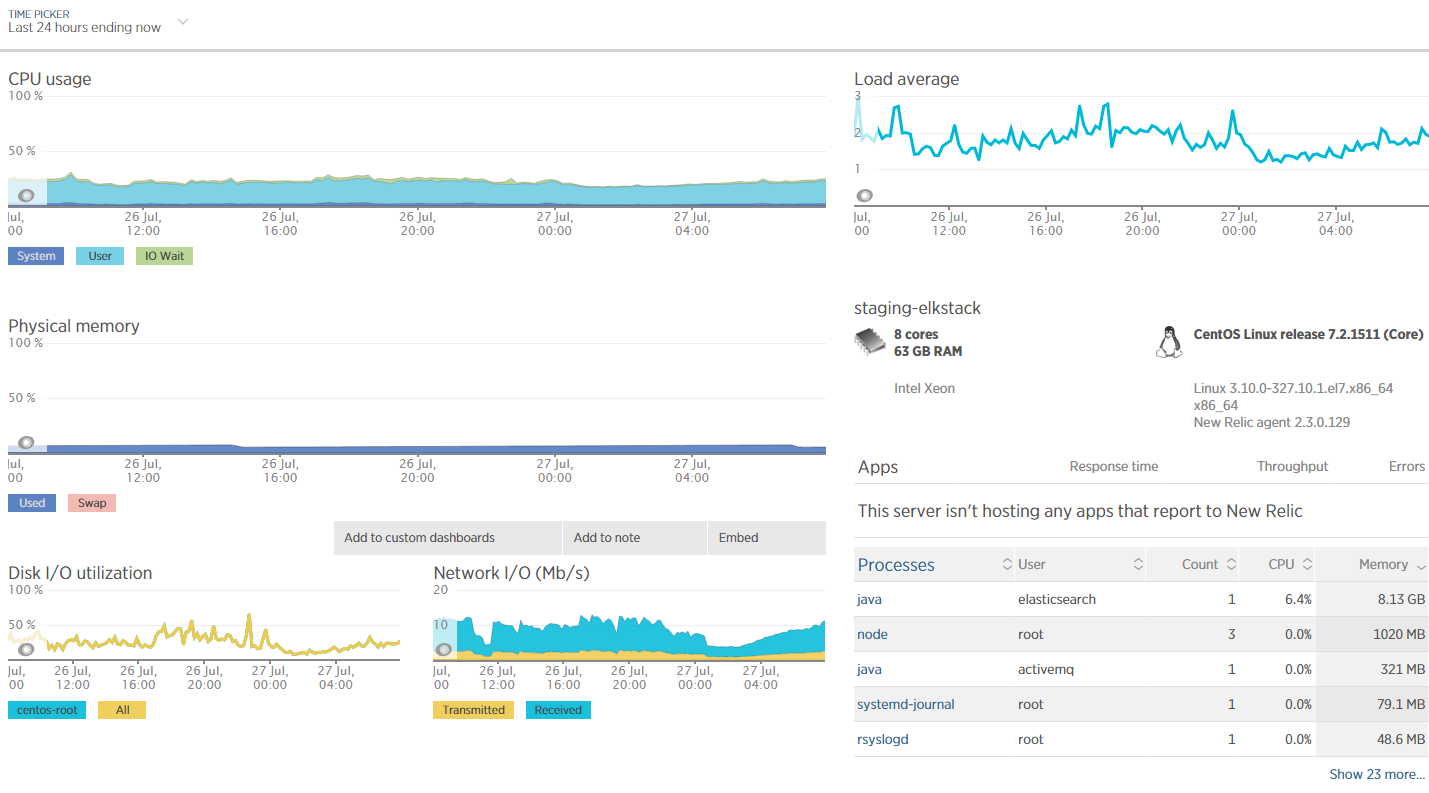
In Newrelic monitor, Elasticsearch instance: