I have a 2 node ES cluster.
They are both linux VMs with 2vCPUs and 4GB RAM. I've kept the default of 5
shards and 1 replica.
I've allocated 2GB of RAM for heap on each box, set memory lock to avoid
swapping, and changed the index refresh interval from 1s to 15s; all in
hope of getting ES to index faster.
I also have a mapping template in place so its not constantly doing an
update_mapping.
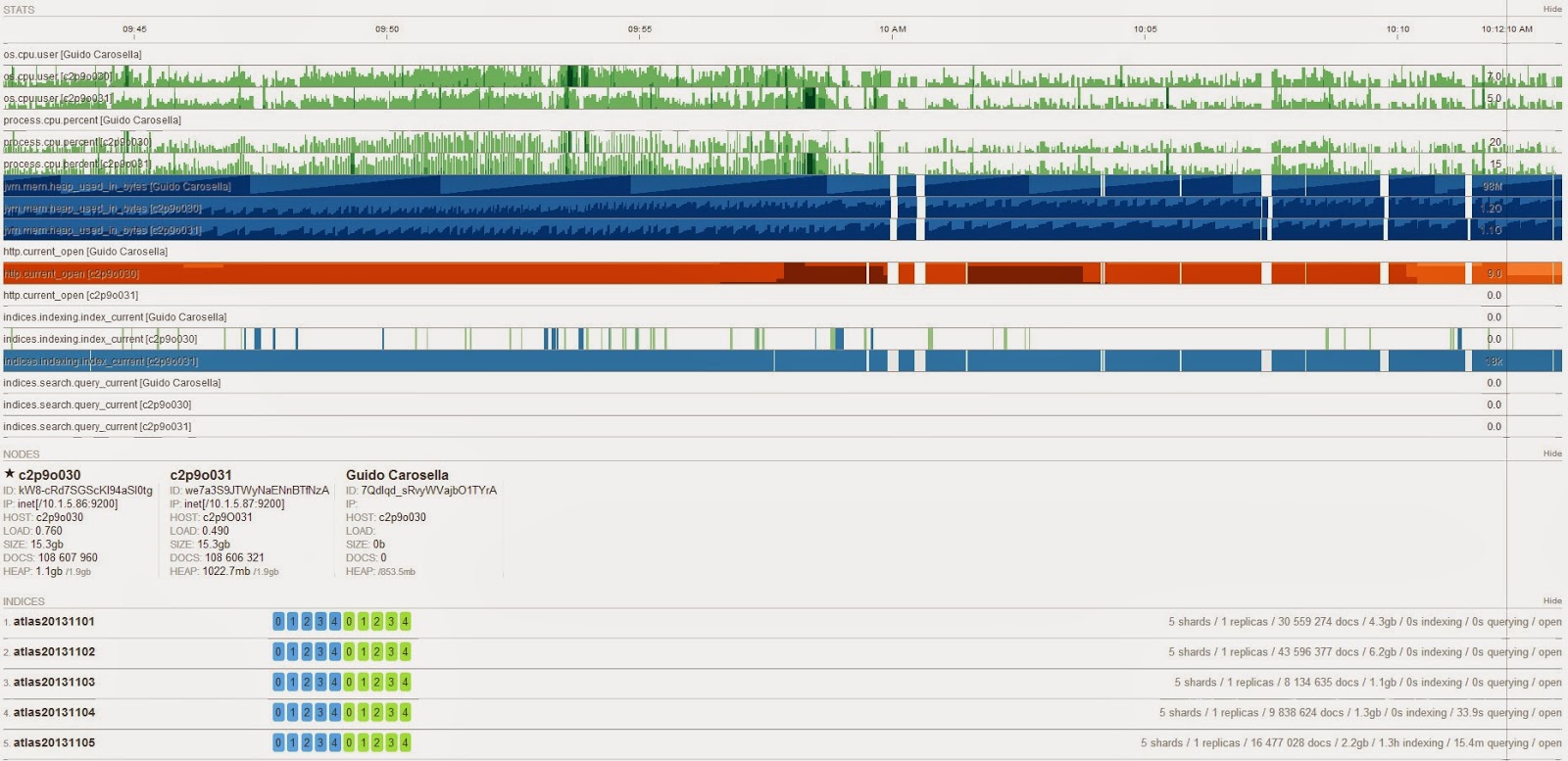
I've downloaded the plugin, Paramedic, and this is what I'm seeing:
indices.indexing.index_current is very high on just one node (up to
18,000), and almost 0 on the other node.
cpu and heap usage is about the same on box servers
My questions is: Why is index_current, which I'm assuming is time to index
in milliseconds, so high on just one node and not the other?
index_current is the number of index operations currently in progress on
this node. There is no need to worry, it just shows indexing activity.
Just as a side note, if you are on a VM, there is not much use in setting
memory lock to avoid swap, because the host OS decides when to swap, not
the guest OS.
If you want maximum indexing speed out of ES, choosing VM is limiting this
a bit. VMs use virtualized store which is not helping in gaining speedy
I/O. You will be better off with non-virtualized servers.
Hi Jorg. Thanks for the reply. Good to know that index_current is the # of
operations and not how long it's taking to index.
However, do you know why only one node is doing all the indexing, while the
other node isn't doing much indexing at all?
Shouldn't we expect the indexing throughput to be evenly distributed across
the 2 nodes?
On Tuesday, November 5, 2013 2:47:12 PM UTC-6, Jörg Prante wrote:
index_current is the number of index operations currently in progress on
this node. There is no need to worry, it just shows indexing activity.
Just as a side note, if you are on a VM, there is not much use in setting
memory lock to avoid swap, because the host OS decides when to swap, not
the guest OS.
If you want maximum indexing speed out of ES, choosing VM is limiting this
a bit. VMs use virtualized store which is not helping in gaining speedy
I/O. You will be better off with non-virtualized servers.
index_current should be 0 if the index is quiet. I'm not sure what you are
doing with the index, what shards the nodes hold, and how the output of the
_stats command looks like over time, so it's not easy to comment. In
general, you are correct, the load should be distributed across the nodes.
To measure the indexing throughput, best thing is to measure numbers in the
client when it sends data over the API, or use monitoring tools. Also note
the client should connect to both nodes, if you want a fair comparison
between the load of the nodes.
Thanks Jorg. In my ES setup, I have the client sending logs over to just
one of the nodes (using its IP address).
Instead of doing this should I have the client sending over to both nodes?
What I mean is should I put a load balancer in front of the 2 nodes so that
load can be round robined between the 2 nodes?
I was under the impression that I can just tell the client to send over to
one node, and ES will take care of the load balancing.
On Tuesday, November 5, 2013 4:00:25 PM UTC-6, Jörg Prante wrote:
index_current should be 0 if the index is quiet. I'm not sure what you are
doing with the index, what shards the nodes hold, and how the output of the
_stats command looks like over time, so it's not easy to comment. In
general, you are correct, the load should be distributed across the nodes.
To measure the indexing throughput, best thing is to measure numbers in the
client when it sends data over the API, or use monitoring tools. Also note
the client should connect to both nodes, if you want a fair comparison
between the load of the nodes.
Yes, you can study where the shards are located. ES will care about
distributing the data to the shards.
What I am concerned - it's maybe a non-issue - that processing the logs
takes extra load on one node. Not sure what you mean by a load balancer. ES
clients can usually connect to one than more IP for failover, but I do not
know what client you use.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.
{kind=link}