After a data node in our cluster (3master, 7data, 3client nodes) died recently, it appears from running out of memory due to field data usage, we added two data nodes, and restarted the one that died. After a couple hours, our cluster was approaching green and got down to a single shard. However, that single shard will not seem to finish and is stuck in INITIALIZING mode. It is one of the daily shards dated to today. Is there anything I can do to force this shard onto a node, or restart its initialization process??
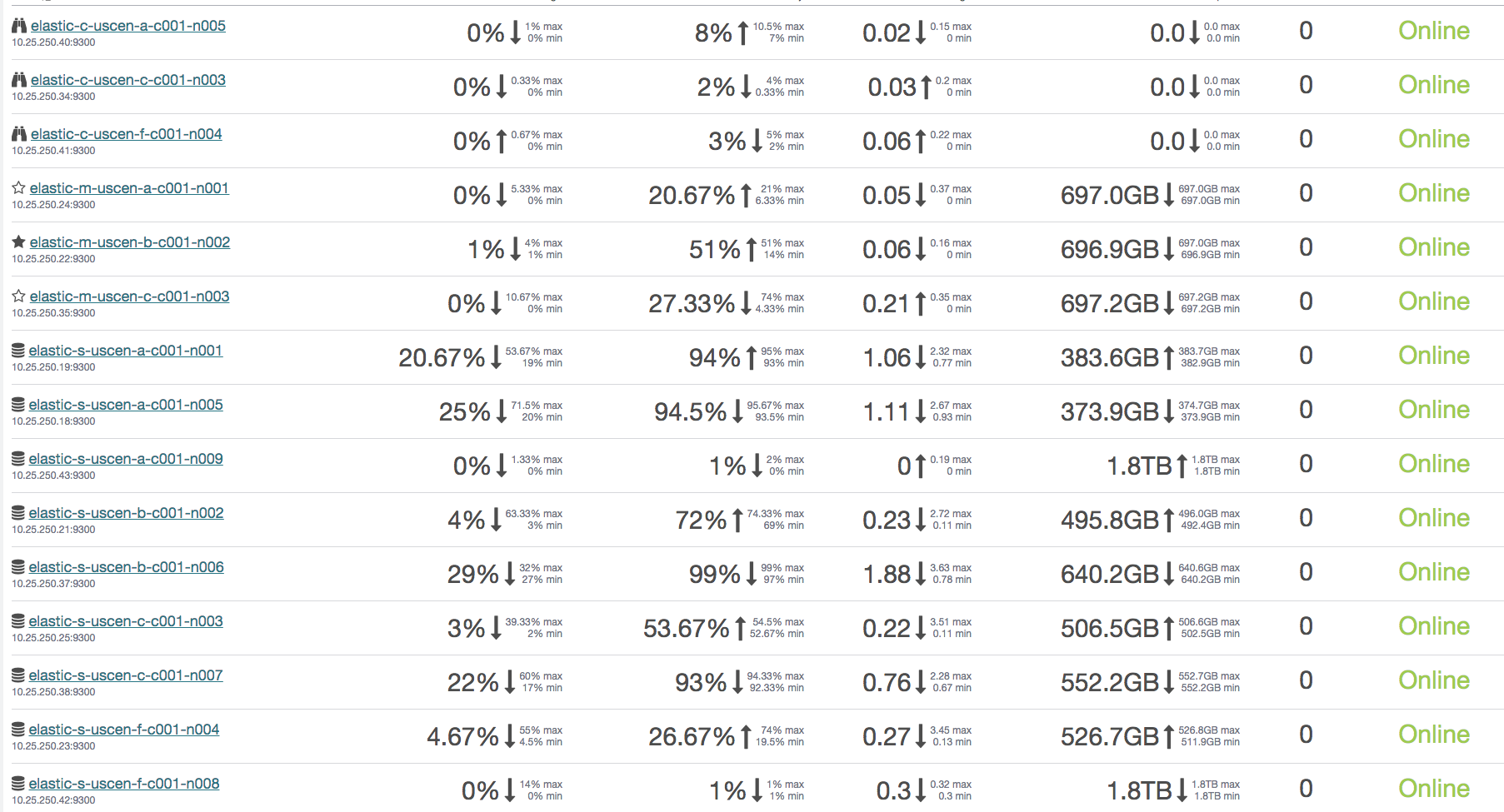
Additionally, it seems that our cluster isn't really re-balancing or distributing its load onto the new data nodes. Here is a screenshot of our marvel display, as you can see, the load is extremely unbalanced across our data nodes.
Is this something that should just balance out over time??
Just a follow up on this, that one shard DID in fact eventually allocate. It just blew my mind because it took around 3 hours for that one 8G shard to process, which was extremely unprecedented, since the rest of our database (2+ TB) had managed to re-allocate over the course of the day.
It did finish however and our cluster is back together.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.