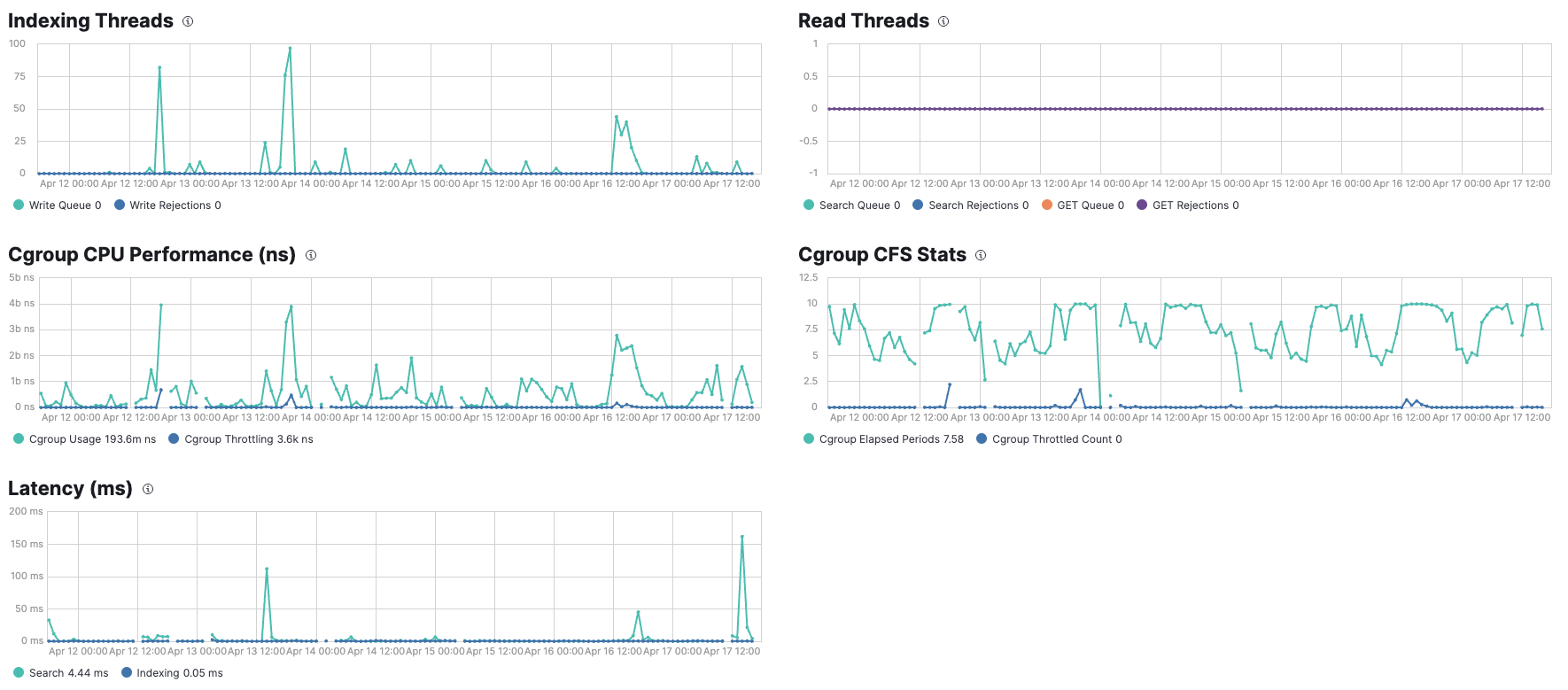
Hello again!
Master logs, before data-node elasticsearch-aud-es-data-wrk-1 left:
{"@timestamp":"2023-04-24T14:28:37.591Z", "log.level": "INFO", "message":"close connection exception caught on transport layer [Netty4TcpChannel{localAddress=/10.2.38.145:9300, remoteAddress=/10.2.19.122:60600, profile=default}], disconnecting from relevant node: Connection timed out", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][transport_worker][T#2]","log.logger":"org.elasticsearch.transport.TcpTransport","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T14:28:43.735Z", "log.level": "INFO", "message":"close connection exception caught on transport layer [Netty4TcpChannel{localAddress=/10.2.38.145:9300, remoteAddress=/10.2.19.122:60620, profile=default}], disconnecting from relevant node: Connection timed out", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][transport_worker][T#2]","log.logger":"org.elasticsearch.transport.TcpTransport","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T14:29:10.359Z", "log.level": "INFO", "message":"close connection exception caught on transport layer [Netty4TcpChannel{localAddress=/10.2.38.145:9300, remoteAddress=/10.2.19.122:60636, profile=default}], disconnecting from relevant node: Connection timed out", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][transport_worker][T#1]","log.logger":"org.elasticsearch.transport.TcpTransport","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:06:28.035Z", "log.level": "INFO", "message":"after [10s] publication of cluster state version [895541] is still waiting for {elasticsearch-aud-es-data-wrk-1}{_p-uv9aASjKMyvpCmlLu-w}{nvUgm5GURpKLchZkRkEZqA}{elasticsearch-aud-es-data-wrk-1}{10.2.60.196}{10.2.60.196:9300}{d}{k8s_node_name=ip-10-2-62-194.ec2.internal, zone=WORKER, xpack.installed=true} [SENT_PUBLISH_REQUEST]", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][cluster_coordination][T#1]","log.logger":"org.elasticsearch.cluster.coordination.Coordinator.CoordinatorPublication","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:06:35.952Z", "log.level": "WARN", "message":"failed to retrieve stats for node [_p-uv9aASjKMyvpCmlLu-w]", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][generic][T#14]","log.logger":"org.elasticsearch.cluster.InternalClusterInfoService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud","error.type":"org.elasticsearch.transport.ReceiveTimeoutTransportException","error.message":"[elasticsearch-aud-es-data-wrk-1][10.2.60.196:9300][cluster:monitor/nodes/stats[n]] request_id [9997711] timed out after [15005ms]","error.stack_trace":"org.elasticsearch.transport.ReceiveTimeoutTransportException: [elasticsearch-aud-es-data-wrk-1][10.2.60.196:9300][cluster:monitor/nodes/stats[n]] request_id [9997711] timed out after [15005ms]\n"}
{"@timestamp":"2023-04-24T15:06:35.959Z", "log.level": "WARN", "message":"failed to retrieve shard stats from node [_p-uv9aASjKMyvpCmlLu-w]", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][management][T#2]","log.logger":"org.elasticsearch.cluster.InternalClusterInfoService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud","error.type":"org.elasticsearch.transport.ReceiveTimeoutTransportException","error.message":"[elasticsearch-aud-es-data-wrk-1][10.2.60.196:9300][indices:monitor/stats[n]] request_id [9997723] timed out after [15005ms]","error.stack_trace":"org.elasticsearch.transport.ReceiveTimeoutTransportException: [elasticsearch-aud-es-data-wrk-1][10.2.60.196:9300][indices:monitor/stats[n]] request_id [9997723] timed out after [15005ms]\n"}
{"@timestamp":"2023-04-24T15:06:48.037Z", "log.level": "WARN", "message":"after [30s] publication of cluster state version [895541] is still waiting for {elasticsearch-aud-es-data-wrk-1}{_p-uv9aASjKMyvpCmlLu-w}{nvUgm5GURpKLchZkRkEZqA}{elasticsearch-aud-es-data-wrk-1}{10.2.60.196}{10.2.60.196:9300}{d}{k8s_node_name=ip-10-2-62-194.ec2.internal, zone=WORKER, xpack.installed=true} [SENT_PUBLISH_REQUEST]", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][clusterApplierService#updateTask][T#1]","log.logger":"org.elasticsearch.cluster.coordination.Coordinator.CoordinatorPublication","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:06:58.042Z", "log.level": "INFO", "message":"after [10s] publication of cluster state version [895542] is still waiting for {elasticsearch-aud-es-data-wrk-1}{_p-uv9aASjKMyvpCmlLu-w}{nvUgm5GURpKLchZkRkEZqA}{elasticsearch-aud-es-data-wrk-1}{10.2.60.196}{10.2.60.196:9300}{d}{k8s_node_name=ip-10-2-62-194.ec2.internal, zone=WORKER, xpack.installed=true} [SENT_PUBLISH_REQUEST]", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][cluster_coordination][T#1]","log.logger":"org.elasticsearch.cluster.coordination.Coordinator.CoordinatorPublication","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:07:18.043Z", "log.level": "WARN", "message":"after [30s] publication of cluster state version [895542] is still waiting for {elasticsearch-aud-es-data-wrk-1}{_p-uv9aASjKMyvpCmlLu-w}{nvUgm5GURpKLchZkRkEZqA}{elasticsearch-aud-es-data-wrk-1}{10.2.60.196}{10.2.60.196:9300}{d}{k8s_node_name=ip-10-2-62-194.ec2.internal, zone=WORKER, xpack.installed=true} [SENT_PUBLISH_REQUEST]", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][clusterApplierService#updateTask][T#1]","log.logger":"org.elasticsearch.cluster.coordination.Coordinator.CoordinatorPublication","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:07:18.049Z", "log.level": "INFO", "current.health":"YELLOW","message":"Cluster health status changed from [GREEN] to [YELLOW] (reason: [{elasticsearch-aud-es-data-wrk-1}{_p-uv9aASjKMyvpCmlLu-w}{nvUgm5GURpKLchZkRkEZqA}{elasticsearch-aud-es-data-wrk-1}{10.2.60.196}{10.2.60.196:9300}{d} reason: followers check retry count exceeded [timeouts=3, failures=0]]).","previous.health":"GREEN","reason":"{elasticsearch-aud-es-data-wrk-1}{_p-uv9aASjKMyvpCmlLu-w}{nvUgm5GURpKLchZkRkEZqA}{elasticsearch-aud-es-data-wrk-1}{10.2.60.196}{10.2.60.196:9300}{d} reason: followers check retry count exceeded [timeouts=3, failures=0]" , "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][masterService#updateTask][T#1]","log.logger":"org.elasticsearch.cluster.routing.allocation.AllocationService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:07:18.055Z", "log.level": "INFO", "message":"node-left[{elasticsearch-aud-es-data-wrk-1}{_p-uv9aASjKMyvpCmlLu-w}{nvUgm5GURpKLchZkRkEZqA}{elasticsearch-aud-es-data-wrk-1}{10.2.60.196}{10.2.60.196:9300}{d} reason: followers check retry count exceeded [timeouts=3, failures=0]], term: 17, version: 895543, delta: removed {{elasticsearch-aud-es-data-wrk-1}{_p-uv9aASjKMyvpCmlLu-w}{nvUgm5GURpKLchZkRkEZqA}{elasticsearch-aud-es-data-wrk-1}{10.2.60.196}{10.2.60.196:9300}{d}}", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][masterService#updateTask][T#1]","log.logger":"org.elasticsearch.cluster.service.MasterService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:07:18.112Z", "log.level": "INFO", "message":"removed {{elasticsearch-aud-es-data-wrk-1}{_p-uv9aASjKMyvpCmlLu-w}{nvUgm5GURpKLchZkRkEZqA}{elasticsearch-aud-es-data-wrk-1}{10.2.60.196}{10.2.60.196:9300}{d}}, term: 17, version: 895543, reason: Publication{term=17, version=895543}", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][clusterApplierService#updateTask][T#1]","log.logger":"org.elasticsearch.cluster.service.ClusterApplierService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:07:18.114Z", "log.level": "INFO", "message":"scheduling reroute for delayed shards in [59.9s] (7 delayed shards)", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][clusterApplierService#updateTask][T#1]","log.logger":"org.elasticsearch.cluster.routing.DelayedAllocationService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:07:18.147Z", "log.level": "WARN", "message":"failed to retrieve stats for node [_p-uv9aASjKMyvpCmlLu-w]", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][generic][T#14]","log.logger":"org.elasticsearch.cluster.InternalClusterInfoService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud","error.type":"org.elasticsearch.transport.NodeDisconnectedException","error.message":"[elasticsearch-aud-es-data-wrk-1][10.2.60.196:9300][cluster:monitor/nodes/stats[n]] disconnected","error.stack_trace":"org.elasticsearch.transport.NodeDisconnectedException: [elasticsearch-aud-es-data-wrk-1][10.2.60.196:9300][cluster:monitor/nodes/stats[n]] disconnected\n"}
{"@timestamp":"2023-04-24T15:07:18.150Z", "log.level": "WARN", "message":"failed to retrieve shard stats from node [_p-uv9aASjKMyvpCmlLu-w]", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][management][T#1]","log.logger":"org.elasticsearch.cluster.InternalClusterInfoService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud","error.type":"org.elasticsearch.transport.NodeDisconnectedException","error.message":"[elasticsearch-aud-es-data-wrk-1][10.2.60.196:9300][indices:monitor/stats[n]] disconnected","error.stack_trace":"org.elasticsearch.transport.NodeDisconnectedException: [elasticsearch-aud-es-data-wrk-1][10.2.60.196:9300][indices:monitor/stats[n]] disconnected\n"}
{"@timestamp":"2023-04-24T15:08:18.047Z", "log.level": "INFO", "message":"scheduling reroute for delayed shards in [0s] (7 delayed shards)", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][masterService#updateTask][T#1]","log.logger":"org.elasticsearch.cluster.routing.DelayedAllocationService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:08:18.132Z", "log.level": "WARN", "message":"[.apm-custom-link][0] marking unavailable shards as stale: [uHHrXJHaThWfE2ML7KtzBw]", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][masterService#updateTask][T#1]","log.logger":"org.elasticsearch.cluster.routing.allocation.AllocationService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:08:18.278Z", "log.level": "WARN", "message":"[.monitoring-kibana-7-2023.04.21][0] marking unavailable shards as stale: [5n9GMhB8TXShQRUW8TCt9Q]", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][masterService#updateTask][T#1]","log.logger":"org.elasticsearch.cluster.routing.allocation.AllocationService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:08:18.330Z", "log.level": "WARN", "message":"[.monitoring-kibana-7-2023.04.22][0] marking unavailable shards as stale: [eJKg9PalRbmnUEcTGTB3ZA]", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][masterService#updateTask][T#1]","log.logger":"org.elasticsearch.cluster.routing.allocation.AllocationService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:08:18.424Z", "log.level": "WARN", "message":"[.tasks][0] marking unavailable shards as stale: [k3okS39eS1eK34bFEIC5ag]", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][masterService#updateTask][T#1]","log.logger":"org.elasticsearch.cluster.routing.allocation.AllocationService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:08:18.654Z", "log.level": "WARN", "message":"[.kibana-event-log-8.6.1-000001][0] marking unavailable shards as stale: [8MFgfVSiTaWJ7Cr5mKSVOw]", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][masterService#updateTask][T#1]","log.logger":"org.elasticsearch.cluster.routing.allocation.AllocationService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:08:18.803Z", "log.level": "WARN", "message":"[.monitoring-kibana-7-2023.04.19][0] marking unavailable shards as stale: [98tPK7ZYQUOs29pDX4dSTg]", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][masterService#updateTask][T#1]","log.logger":"org.elasticsearch.cluster.routing.allocation.AllocationService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:09:55.968Z", "log.level": "WARN", "message":"[.monitoring-es-7-2023.04.20][0] marking unavailable shards as stale: [gg3Gn-uOQl61bK7dK3QReA]", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][masterService#updateTask][T#1]","log.logger":"org.elasticsearch.cluster.routing.allocation.AllocationService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:09:56.190Z", "log.level": "INFO", "current.health":"GREEN","message":"Cluster health status changed from [YELLOW] to [GREEN] (reason: [shards started [[.monitoring-es-7-2023.04.20][0]]]).","previous.health":"YELLOW","reason":"shards started [[.monitoring-es-7-2023.04.20][0]]" , "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][masterService#updateTask][T#1]","log.logger":"org.elasticsearch.cluster.routing.allocation.AllocationService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:14:38.951Z", "log.level": "INFO", "message":"[8776374_23-04-24_15-14-35] creating index, cause [api], templates [], shards [13]/[0]", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][masterService#updateTask][T#1]","log.logger":"org.elasticsearch.cluster.metadata.MetadataCreateIndexService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:14:39.124Z", "log.level": "INFO", "current.health":"GREEN","message":"Cluster health status changed from [YELLOW] to [GREEN] (reason: [shards started [[8776374_23-04-24_15-14-35][6], [8776374_23-04-24_15-14-35][4], [8776374_23-04-24_15-14-35][7], [8776374_23-04-24_15-14-35][3], [8776374_23-04-24_15-14-35][2], [8776374_23-04-24_15-14-35][11], [8776374_23-04-24_15-14-35][1], [8776374_23-04-24_15-14-35][8], [8776374_23-04-24_15-14-35][10], [8776374_23-04-24_15-14-35][12], ... [12 items in total]]]).","previous.health":"YELLOW","reason":"shards started [[8776374_23-04-24_15-14-35][6], [8776374_23-04-24_15-14-35][4], [8776374_23-04-24_15-14-35][7], [8776374_23-04-24_15-14-35][3], [8776374_23-04-24_15-14-35][2], [8776374_23-04-24_15-14-35][11], [8776374_23-04-24_15-14-35][1], [8776374_23-04-24_15-14-35][8], [8776374_23-04-24_15-14-35][10], [8776374_23-04-24_15-14-35][12], ... [12 items in total]]" , "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][masterService#updateTask][T#1]","log.logger":"org.elasticsearch.cluster.routing.allocation.AllocationService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:14:40.127Z", "log.level": "INFO", "message":"[8776374_23-04-24_15-14-35/KZkYD3UlTyek5tGcWss4YQ] update_mapping [_doc]", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][masterService#updateTask][T#1]","log.logger":"org.elasticsearch.cluster.metadata.MetadataMappingService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:14:40.193Z", "log.level": "INFO", "message":"[8776374_23-04-24_15-14-35/KZkYD3UlTyek5tGcWss4YQ] update_mapping [_doc]", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][masterService#updateTask][T#1]","log.logger":"org.elasticsearch.cluster.metadata.MetadataMappingService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:14:40.240Z", "log.level": "INFO", "message":"[8776374_23-04-24_15-14-35/KZkYD3UlTyek5tGcWss4YQ] update_mapping [_doc]", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][masterService#updateTask][T#1]","log.logger":"org.elasticsearch.cluster.metadata.MetadataMappingService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:14:40.293Z", "log.level": "INFO", "message":"[8776374_23-04-24_15-14-35/KZkYD3UlTyek5tGcWss4YQ] update_mapping [_doc]", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][masterService#updateTask][T#1]","log.logger":"org.elasticsearch.cluster.metadata.MetadataMappingService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:14:40.301Z", "log.level": "INFO", "message":"[8776374_23-04-24_15-14-35/KZkYD3UlTyek5tGcWss4YQ] update_mapping [_doc]", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][masterService#updateTask][T#1]","log.logger":"org.elasticsearch.cluster.metadata.MetadataMappingService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:14:40.354Z", "log.level": "INFO", "message":"[8776374_23-04-24_15-14-35/KZkYD3UlTyek5tGcWss4YQ] update_mapping [_doc]", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][masterService#updateTask][T#1]","log.logger":"org.elasticsearch.cluster.metadata.MetadataMappingService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:14:46.911Z", "log.level": "INFO", "message":"node-join[{elasticsearch-aud-es-data-wrk-1}{_p-uv9aASjKMyvpCmlLu-w}{ILLoNX5WT_myTUT6tHyelg}{elasticsearch-aud-es-data-wrk-1}{10.2.61.208}{10.2.61.208:9300}{d} joining after restart, removed [7.4m/448837ms] ago with reason [followers check retry count exceeded [timeouts=3, failures=0]]], term: 17, version: 895655, delta: added {{elasticsearch-aud-es-data-wrk-1}{_p-uv9aASjKMyvpCmlLu-w}{ILLoNX5WT_myTUT6tHyelg}{elasticsearch-aud-es-data-wrk-1}{10.2.61.208}{10.2.61.208:9300}{d}}", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][masterService#updateTask][T#1]","log.logger":"org.elasticsearch.cluster.service.MasterService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:14:48.356Z", "log.level": "INFO", "message":"added {{elasticsearch-aud-es-data-wrk-1}{_p-uv9aASjKMyvpCmlLu-w}{ILLoNX5WT_myTUT6tHyelg}{elasticsearch-aud-es-data-wrk-1}{10.2.61.208}{10.2.61.208:9300}{d}}, term: 17, version: 895655, reason: Publication{term=17, version=895655}", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][clusterApplierService#updateTask][T#1]","log.logger":"org.elasticsearch.cluster.service.ClusterApplierService","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:18:35.863Z", "log.level": "INFO", "message":"close connection exception caught on transport layer [Netty4TcpChannel{localAddress=/10.2.38.145:9300, remoteAddress=/10.2.60.196:47424, profile=default}], disconnecting from relevant node: Connection timed out", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][transport_worker][T#1]","log.logger":"org.elasticsearch.transport.TcpTransport","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:18:35.863Z", "log.level": "INFO", "message":"close connection exception caught on transport layer [Netty4TcpChannel{localAddress=/10.2.38.145:9300, remoteAddress=/10.2.60.196:47440, profile=default}], disconnecting from relevant node: Connection timed out", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][transport_worker][T#2]","log.logger":"org.elasticsearch.transport.TcpTransport","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:18:35.863Z", "log.level": "INFO", "message":"close connection exception caught on transport layer [Netty4TcpChannel{localAddress=/10.2.38.145:9300, remoteAddress=/10.2.60.196:47488, profile=default}], disconnecting from relevant node: Connection timed out", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][transport_worker][T#1]","log.logger":"org.elasticsearch.transport.TcpTransport","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
{"@timestamp":"2023-04-24T15:18:35.863Z", "log.level": "INFO", "message":"close connection exception caught on transport layer [Netty4TcpChannel{localAddress=/10.2.38.145:9300, remoteAddress=/10.2.60.196:47416, profile=default}], disconnecting from relevant node: Connection timed out", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[elasticsearch-aud-es-master-1][transport_worker][T#2]","log.logger":"org.elasticsearch.transport.TcpTransport","elasticsearch.cluster.uuid":"2xZgtNgpTAmv_kfkn-jxmw","elasticsearch.node.id":"G4IlCnDPSey6vfW8VvLC1g","elasticsearch.node.name":"elasticsearch-aud-es-master-1","elasticsearch.cluster.name":"elasticsearch-aud"}
here are the dump files (every 10s with date printed at the beginning):
https://drive.google.com/drive/folders/1GUtBNjMlJ7Fj5KS6qVI5t8VVdBe-Jrq9?usp=share_link