We have a development / proof of concept / begging for funds stack that has been running for several months. I upgraded from 5.5 to 5.6.5 and everything seemed OK, then I upgraded to 6.1.1. Platform is physical (junk pile) servers running RHEL 7 and NL SAS PERC raid.
I have some pretty large python DSL queries that run either daily or every 8 hours processing the respective past 24/8 hours of data to product reports or data extracts. Before 6.1.1 they ran if a minute or two, they were stable, so I hadn't been watching them.
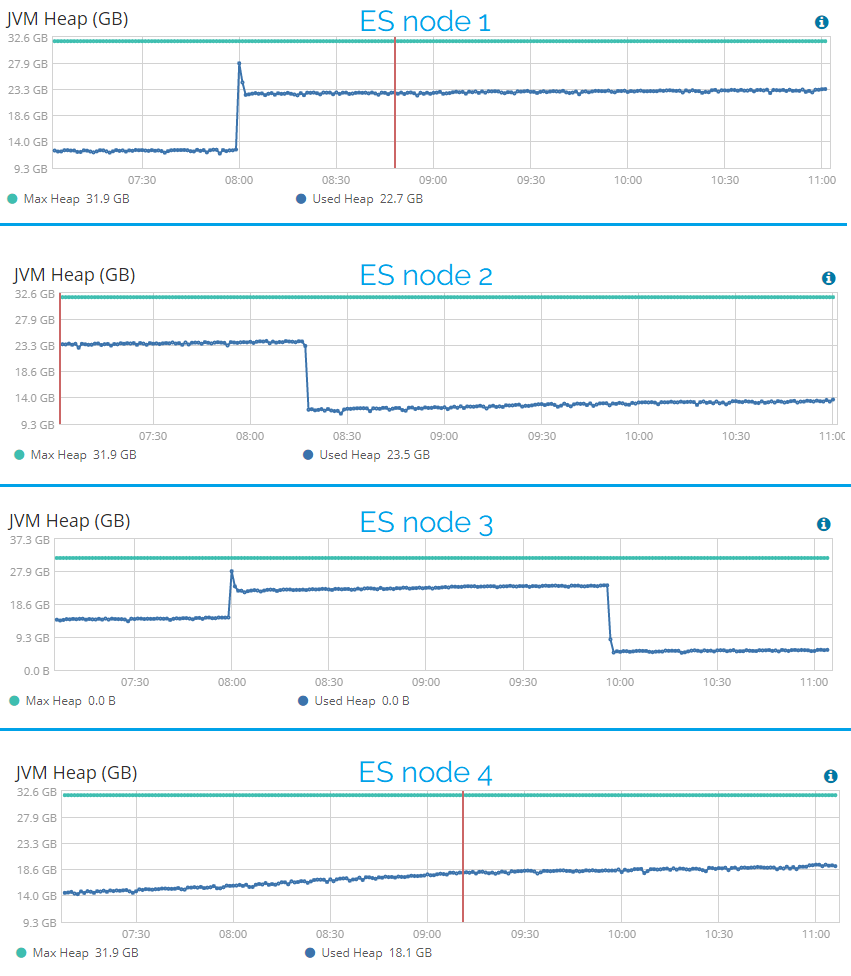
Since 6.1.1, one of these causes the cluster to lock up, the other runs slow, seems to block indexing and generates a LOT of gc messages.
The data nodes have a 32G heap.
Any ideas what to look for?
Node stats:
{
"_nodes": {
"total": 7,
"successful": 7,
"failed": 0
},
"cluster_name": "elk-poc2",
"timestamp": 1515338351882,
"status": "green",
"indices": {
"count": 352,
"shards": {
"total": 2730,
"primaries": 1365,
"replication": 1,
"index": {
"shards": {
"min": 2,
"max": 10,
"avg": 7.755681818181818
},
"primaries": {
"min": 1,
"max": 5,
"avg": 3.877840909090909
},
"replication": {
"min": 1,
"max": 1,
"avg": 1
}
}
},
"docs": {
"count": 13129195226,
"deleted": 263482
},
"store": {
"size": "12.3tb",
"size_in_bytes": 13569499731142
},
"fielddata": {
"memory_size": "2.2mb",
"memory_size_in_bytes": 2409544,
"evictions": 0
},
"query_cache": {
"memory_size": "0b",
"memory_size_in_bytes": 0,
"total_count": 0,
"hit_count": 0,
"miss_count": 0,
"cache_size": 0,
"cache_count": 0,
"evictions": 0
},
"completion": {
"size": "0b",
"size_in_bytes": 0
},
"segments": {
"count": 68749,
"memory": "28.2gb",
"memory_in_bytes": 30360765157,
"terms_memory": "23gb",
"terms_memory_in_bytes": 24696600599,
"stored_fields_memory": "4.2gb",
"stored_fields_memory_in_bytes": 4563301448,
"term_vectors_memory": "0b",
"term_vectors_memory_in_bytes": 0,
"norms_memory": "21.8mb",
"norms_memory_in_bytes": 22861120,
"points_memory": "641.5mb",
"points_memory_in_bytes": 672761010,
"doc_values_memory": "386.4mb",
"doc_values_memory_in_bytes": 405240980,
"index_writer_memory": "164.5mb",
"index_writer_memory_in_bytes": 172520140,
"version_map_memory": "1mb",
"version_map_memory_in_bytes": 1134417,
"fixed_bit_set": "2.7mb",
"fixed_bit_set_memory_in_bytes": 2910384,
"max_unsafe_auto_id_timestamp": 1515286348612,
"file_sizes": {}
}
},
"nodes": {
"count": {
"total": 7,
"data": 4,
"coordinating_only": 0,
"master": 4,
"ingest": 7
},
"versions": [
"6.1.1"
],
"os": {
"available_processors": 168,
"allocated_processors": 168,
"names": [
{
"name": "Linux",
"count": 7
}
],
"mem": {
"total": "368.2gb",
"total_in_bytes": 395400986624,
"free": "6gb",
"free_in_bytes": 6456979456,
"used": "362.2gb",
"used_in_bytes": 388944007168,
"free_percent": 2,
"used_percent": 98
}
},
"process": {
"cpu": {
"percent": 31
},
"open_file_descriptors": {
"min": 725,
"max": 2223,
"avg": 1565
}
},
"jvm": {
"max_uptime": "1.8d",
"max_uptime_in_millis": 158225585,
"versions": [
{
"version": "1.8.0_151",
"vm_name": "OpenJDK 64-Bit Server VM",
"vm_version": "25.151-b12",
"vm_vendor": "Oracle Corporation",
"count": 7
}
],
"mem": {
"heap_used": "68.8gb",
"heap_used_in_bytes": 73908181168,
"heap_max": "174.9gb",
"heap_max_in_bytes": 187879391232
},
"threads": 1844
},
"fs": {
"total": "58.2tb",
"total_in_bytes": 64056450248704,
"free": "45.9tb",
"free_in_bytes": 50467831771136,
"available": "45.9tb",
"available_in_bytes": 50467831771136
},
"plugins": [
{
"name": "ingest-geoip",
"version": "6.1.1",
"description": "Ingest processor that uses looksup geo data based on ip adresses using the Maxmind geo database",
"classname": "org.elasticsearch.ingest.geoip.IngestGeoIpPlugin",
"has_native_controller": false,
"requires_keystore": false
},
{
"name": "x-pack",
"version": "6.1.1",
"description": "Elasticsearch Expanded Pack Plugin",
"classname": "org.elasticsearch.xpack.XPackPlugin",
"has_native_controller": true,
"requires_keystore": true
}
],
"network_types": {
"transport_types": {
"security4": 7
},
"http_types": {
"security4": 7
}
}
}
}