Good day
I was install plugin yesterday. with manual about rolling upgrade i do next things:
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.enable": "none"
}
}
POST _flush/synced
systemctl stop elasticsearch
/usr/share/elasticsearch/bin/elasticsearch-plugin install repository-s3
systemctl start elasticsearch
curl -XPUT localhost:9322/_cluster/settings -d '{
"transient": {
"cluster.routing.allocation.enable": "all"
}
}'
Before all i do { "number_of_replicas" :0 } due to lack of space.
Now i have:
"version" : {
"number" : "5.0.0",
"build_hash" : "253032b",
"build_date" : "2016-10-26T04:37:51.531Z",
"build_snapshot" : false,
"lucene_version" : "6.2.0"
}
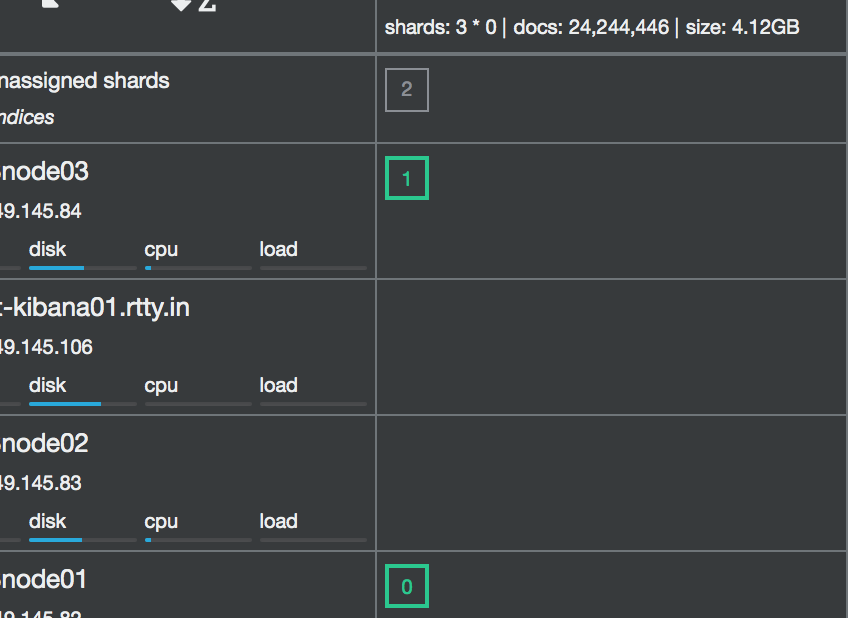
cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
backup-itest01log red 4 3 3355 3348 0 0 783 0 - 81.1%
heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
60 82 6 1.01 0.47 0.28 - - kibana01
18 86 9 0.50 0.66 1.00 mdi - node02
56 88 8 0.04 0.40 0.81 mdi * node01
22 91 9 0.15 0.40 0.71 mdi - node03
shards disk.indices disk.used disk.avail disk.total disk.percent node
1118 592.9gb 935gb 813.2gb 1.7tb 53 node02
1119 629.9gb 723gb 1tb 1.7tb 41 node01
1118 631.5gb 964.8gb 783.4gb 1.7tb 55 node03
783 UNASSIGNED
And it dont't change all the night. node01(master) and client node(kibana01) i don't touch yet. only node02 and 03
Help me please!