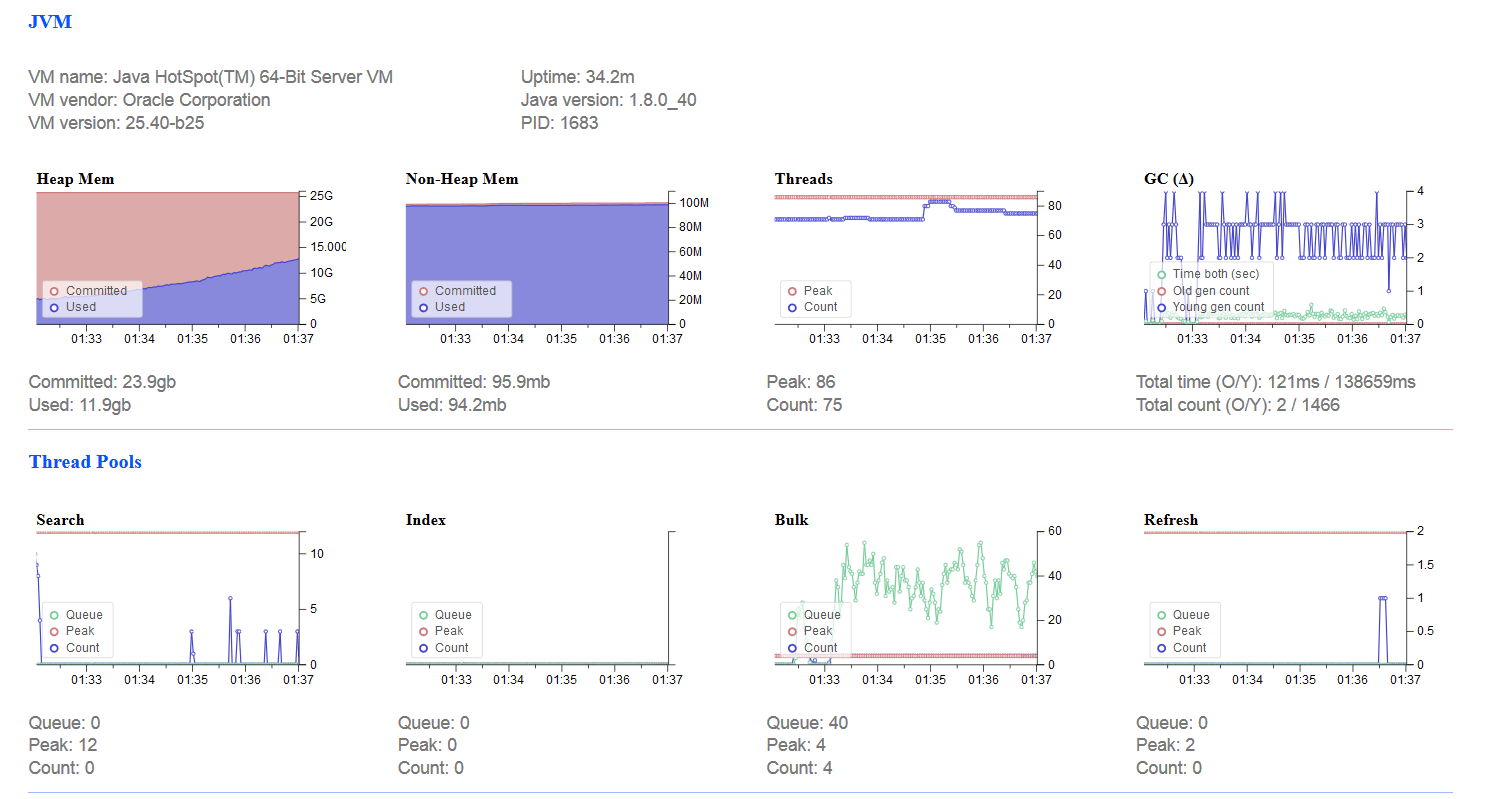
I seems bulk indexing is using a lot of memory. It is not for long, but the day sees much more indexing demand than shown here. Is there a way I can reduce memory required during indexing, while still keeping the indexing rate high?
There are 10 nodes in the cluster, but this node is the "primary" containing all shards. The 9 other nodes are recipients of bulk index requests (and containing some replica shards). Each of the 9 have a daemon inserting 5000 documents per bulk request. Each document is about 1K. It works out to a rate of about 400*9 documents per second. Faster would be nicer, but this primary node is the bottleneck.
Here is an example of what it looks like just before ES dies:
If you are using 1 replica and two zones, where one of the zones only have a single node, this will be indexing all records, which will lead to much higher load than the other nodes. Elasticsearch is usually deployed in clusters where all nodes are equal so that load can be evenly distributed. What is it you are trying to achieve using this setup?
I am aware that a node with more shards will have more load. I am concerned with what I can do to reduce indexing load, or move the work to the other nodes. Maybe the fact this one node is master? Should I assign the master to be in the other zone? Maybe a slave with all shards will use less memory?
My setup is designed to achieve minimal price on AWS. The benefit to having one machine in a zone is it's 1/2 the cost of two machines, and 1/3 the cost of three machines.
I added a "coordinator node" in the same zone as the 9 nodes. This coordinator is the master (node.master: true), and has no shards (node.data: false). Here is the coordinator under heavy indexing load:
What's important to see is the rate of memory consumption is much smaller. Hopefully this leads to less OOM events that crash this node. I believe the growth in memory is proportional to the number of primary shards on a node. By moving the master to the other zone, it appears my primary node is assigned less primary shards, and so has lower memory consumption.
This is not perfect, eventually the primary node's shards are designated primary, and the memory consumption rate goes up accordingly. I hope I can control the algorithm that determines what shard is declared primary; preferring primaries be assigned to the zone with the most nodes.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.