We experienced a master re-election, seemingly due to a timeout (or underlying throttling of the ec2 discovery mechanism in AWS, we're working through that with Amazon) . Regardless, the previous master got into a bad state similar to https://github.com/elasticsearch/elasticsearch/issues/3017 (excised from cluster, still reporting green health, needed a restart to join).
As a result or related to this, I'd has one replica in a relocating state for about 18 hours. I let it run to see if it would complete, but I'm wondering if it will at this point.
{
"cluster_name" : "es_cayovaprod_0001",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 19,
"number_of_data_nodes" : 6,
"active_primary_shards" : 101,
"active_shards" : 292,
"relocating_shards" : 1,
"initializing_shards" : 1,
"unassigned_shards" : 0
}
According to big desk, the cluster state for the replica/shard is -
ip-10-239-110-94: replica, relocating
ip-10-65-49-148: replica, recovering
ip-10-36-174-153: primary, green
ip-10-36-201-76: replica, green
The index in question is configured to have 2 replicas.
The first two nodes in transition show a high cpu relative to the other nodes (https://pbs.twimg.com/media/BKS1BC-CIAE5h__.png:large), according to htop they're sitting at about 33% which doesn't seem unreasonable in itself (the length of time at that level is the concern) .
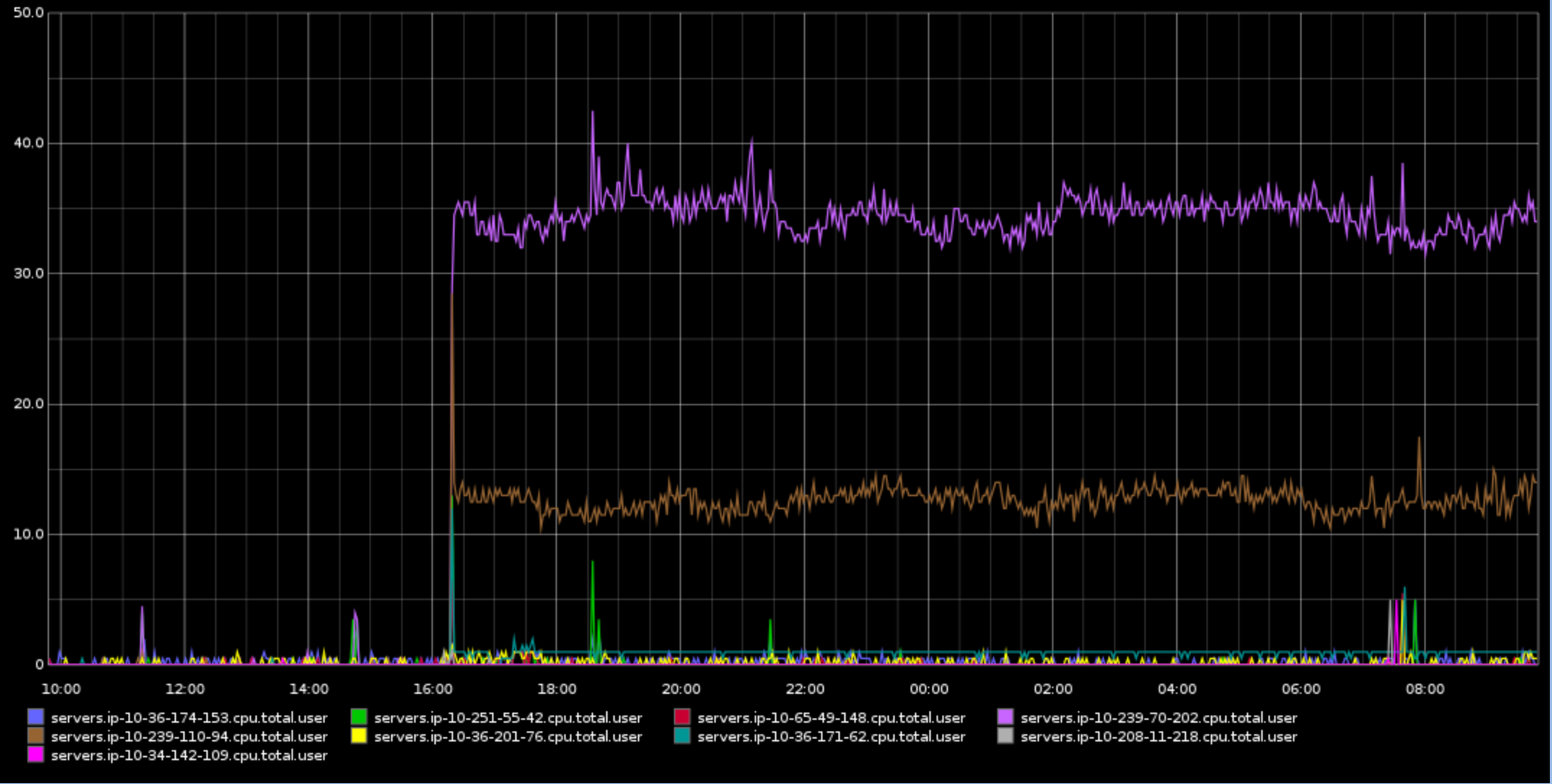{kind=link}
The log for ip-10-239-110-94 around the time of the start of the CPU burst -
"""
[2013-05-14 15:18:18,219][WARN ][indices.cluster ] [ip-10-239-110-94] [objects_0001][22] master [[ip-10-36-171-62][j-Gbp_DDSHqYk3e25MPf4Q][inet[/10.36.171.62:9300]]{data=false, master=true, zone=eu-west-1a}] marked shard as started, but shard have not been created, mark shard as failed
[2013-05-14 15:18:18,219][WARN ][cluster.action.shard ] [ip-10-239-110-94] sending failed shard for [objects_0001][22], node[ybnrwqQ8RPCa69L4SqE7bA], [P], s[STARTED], reason [master [ip-10-36-171-62][j-Gbp_DDSHqYk3e25MPf4Q][inet[/10.36.171.62:9300]]{data=false, master=true, zone=eu-west-1a} marked shard as started, but shard have not been created, mark shard as failed]
[2013-05-14 15:54:03,981][DEBUG][discovery.zen.fd ] [ip-10-239-110-94] [master] restarting fault detection against master [[ip-10-34-144-149][IsP0kjtRS6KJ-9R3hZehwQ][inet[/10.34.144.149:9300]]{data=false, master=true, zone=eu-west-1c}], reason [new cluster stare received and we monitor the wrong master [[ip-10-36-171-62][j-Gbp_DDSHqYk3e25MPf4Q][inet[/10.36.171.62:9300]]{data=false, master=true, zone=eu-west-1a}]]
[2013-05-14 16:25:38,339][DEBUG][discovery.zen.fd ] [ip-10-239-110-94] [master] restarting fault detection against master [[ip-10-36-171-62][j-Gbp_DDSHqYk3e25MPf4Q][inet[/10.36.171.62:9300]]{data=false, master=true, zone=eu-west-1a}], reason [new cluster stare received and we monitor the wrong master [[ip-10-34-144-149][IsP0kjtRS6KJ-9R3hZehwQ][inet[/10.34.144.149:9300]]{data=false, master=true, zone=eu-west-1c}]]
[2013-05-14 16:25:45,943][INFO ][cluster.service ] [ip-10-239-110-94] added {[ip-10-36-139-232][COIAyFiiRumWsc1h_c1uhQ][inet[/10.36.139.232:9300]]{client=true, data=false},}, reason: zen-disco-receive(from master [[ip-10-36-171-62][j-Gbp_DDSHqYk3e25MPf4Q][inet[/10.36.171.62:9300]]{data=false, master=true, zone=eu-west-1a}])
[2013-05-14 16:25:45,978][INFO ][cluster.service ] [ip-10-239-110-94] added {[ip-10-36-129-154][an52EiHdTaiFBvaxzq-KOQ][inet[/10.36.129.154:9302]]{client=true, data=false},}, reason: zen-disco-receive(from master [[ip-10-36-171-62][j-Gbp_DDSHqYk3e25MPf4Q][inet[/10.36.171.62:9300]]{data=false, master=true, zone=eu-west-1a}])
[2013-05-14 16:25:45,998][INFO ][cluster.service ] [ip-10-239-110-94] added {[ip-10-36-129-154][VZzB17qkTneJNJLZizFtcA][inet[/10.36.129.154:9300]]{client=true, data=false},}, reason: zen-disco-receive(from master [[ip-10-36-171-62][j-Gbp_DDSHqYk3e25MPf4Q][inet[/10.36.171.62:9300]]{data=false, master=true, zone=eu-west-1a}])
[2013-05-14 16:26:02,795][INFO ][cluster.service ] [ip-10-239-110-94] added {[ip-10-34-144-149][6EbGNFdOQv6_ny2_jdPQyg][inet[/10.34.144.149:9300]]{data=false, master=true, zone=eu-west-1c},}, reason: zen-disco-receive(from master [[ip-10-36-171-62][j-Gbp_DDSHqYk3e25MPf4Q][inet[/10.36.171.62:9300]]{data=false, master=true, zone=eu-west-1a}])
[2013-05-14 16:29:09,448][INFO ][cluster.service ] [ip-10-239-110-94] removed {[ip-10-34-144-149][6EbGNFdOQv6_ny2_jdPQyg][inet[/10.34.144.149:9300]]{data=false, master=true, zone=eu-west-1c},}, reason: zen-disco-receive(from master [[ip-10-36-171-62][j-Gbp_DDSHqYk3e25MPf4Q][inet[/10.36.171.62:9300]]{data=false, master=true, zone=eu-west-1a}])
[2013-05-14 16:29:46,612][INFO ][cluster.service ] [ip-10-239-110-94] added {[ip-10-34-144-149][UM03BjRfS3OmTu9QLcWneQ][inet[/10.34.144.149:9300]]{data=false, master=true, zone=eu-west-1c},}, reason: zen-disco-receive(from master [[ip-10-36-171-62][j-Gbp_DDSHqYk3e25MPf4Q][inet[/10.36.171.62:9300]]{data=false, master=true, zone=eu-west-1a}])
"""
with no entries since then. The log for ip-10-65-49-148 around the time of the start of the CPU burst -
"""
[2013-05-14 15:18:03,773][DEBUG][discovery.zen.fd ] [ip-10-65-49-148] [master] restarting fault detection against master [[ip-10-36-171-62][j-Gbp_DDSHqYk3e25MPf4Q][inet[/10.36.171.62:9300]]{data=false, master=true, zone=eu-west-1a}], reason [new cluster stare received and we monitor the wrong master [[ip-10-34-144-149][IsP0kjtRS6KJ-9R3hZehwQ][inet[/10.34.144.149:9300]]{data=false, master=true, zone=eu-west-1c}]]
[2013-05-14 15:18:03,773][INFO ][cluster.service ] [ip-10-65-49-148] master {new [ip-10-36-171-62][j-Gbp_DDSHqYk3e25MPf4Q][inet[/10.36.171.62:9300]]{data=false, master=true, zone=eu-west-1a}, previous [ip-10-34-144-149][IsP0kjtRS6KJ-9R3hZehwQ][inet[/10.34.144.149:9300]]{data=false, master=true, zone=eu-west-1c}}, removed {[ip-10-34-144-149][IsP0kjtRS6KJ-9R3hZehwQ][inet[/10.34.144.149:9300]]{data=false, master=true, zone=eu-west-1c},}, reason: zen-disco-receive(from master [[ip-10-36-171-62][j-Gbp_DDSHqYk3e25MPf4Q][inet[/10.36.171.62:9300]]{data=false, master=true, zone=eu-west-1a}])
[2013-05-14 15:54:03,982][DEBUG][discovery.zen.fd ] [ip-10-65-49-148] [master] restarting fault detection against master [[ip-10-34-144-149][IsP0kjtRS6KJ-9R3hZehwQ][inet[/10.34.144.149:9300]]{data=false, master=true, zone=eu-west-1c}], reason [new cluster stare received and we monitor the wrong master [[ip-10-36-171-62][j-Gbp_DDSHqYk3e25MPf4Q][inet[/10.36.171.62:9300]]{data=false, master=true, zone=eu-west-1a}]]
[2013-05-14 16:25:38,340][DEBUG][discovery.zen.fd ] [ip-10-65-49-148] [master] restarting fault detection against master [[ip-10-36-171-62][j-Gbp_DDSHqYk3e25MPf4Q][inet[/10.36.171.62:9300]]{data=false, master=true, zone=eu-west-1a}], reason [new cluster stare received and we monitor the wrong master [[ip-10-34-144-149][IsP0kjtRS6KJ-9R3hZehwQ][inet[/10.34.144.149:9300]]{data=false, master=true, zone=eu-west-1c}]]
[2013-05-14 16:25:45,944][INFO ][cluster.service ] [ip-10-65-49-148] added {[ip-10-36-139-232][COIAyFiiRumWsc1h_c1uhQ][inet[/10.36.139.232:9300]]{client=true, data=false},}, reason: zen-disco-receive(from master [[ip-10-36-171-62][j-Gbp_DDSHqYk3e25MPf4Q][inet[/10.36.171.62:9300]]{data=false, master=true, zone=eu-west-1a}])
[2013-05-14 16:25:45,979][INFO ][cluster.service ] [ip-10-65-49-148] added {[ip-10-36-129-154][an52EiHdTaiFBvaxzq-KOQ][inet[/10.36.129.154:9302]]{client=true, data=false},}, reason: zen-disco-receive(from master [[ip-10-36-171-62][j-Gbp_DDSHqYk3e25MPf4Q][inet[/10.36.171.62:9300]]{data=false, master=true, zone=eu-west-1a}])
[2013-05-14 16:25:45,998][INFO ][cluster.service ] [ip-10-65-49-148] added {[ip-10-36-129-154][VZzB17qkTneJNJLZizFtcA][inet[/10.36.129.154:9300]]{client=true, data=false},}, reason: zen-disco-receive(from master [[ip-10-36-171-62][j-Gbp_DDSHqYk3e25MPf4Q][inet[/10.36.171.62:9300]]{data=false, master=true, zone=eu-west-1a}])
[2013-05-14 16:26:02,797][INFO ][cluster.service ] [ip-10-65-49-148] added {[ip-10-34-144-149][6EbGNFdOQv6_ny2_jdPQyg][inet[/10.34.144.149:9300]]{data=false, master=true, zone=eu-west-1c},}, reason: zen-disco-receive(from master [[ip-10-36-171-62][j-Gbp_DDSHqYk3e25MPf4Q][inet[/10.36.171.62:9300]]{data=false, master=true, zone=eu-west-1a}])
[2013-05-14 16:29:09,452][INFO ][cluster.service ] [ip-10-65-49-148] removed {[ip-10-34-144-149][6EbGNFdOQv6_ny2_jdPQyg][inet[/10.34.144.149:9300]]{data=false, master=true, zone=eu-west-1c},}, reason: zen-disco-receive(from master [[ip-10-36-171-62][j-Gbp_DDSHqYk3e25MPf4Q][inet[/10.36.171.62:9300]]{data=false, master=true, zone=eu-west-1a}])
[2013-05-14 16:29:46,613][INFO ][cluster.service ] [ip-10-65-49-148] added {[ip-10-34-144-149][UM03BjRfS3OmTu9QLcWneQ][inet[/10.34.144.149:9300]]{data=false, master=true, zone=eu-west-1c},}, reason: zen-disco-receive(from master [[ip-10-36-171-62][j-Gbp_DDSHqYk3e25MPf4Q][inet[/10.36.171.62:9300]]{data=false, master=true, zone=eu-west-1a}])
"""
again with no entries since then.
I'm not sure how to interpret the logs, but it is possible these nodes thought they were working against two masters (or the wrong master) for a period of time?
I'm wondering -
-
is there anything I can or should do to get this relocation to complete and have the two nodes quiesce their cpu usage?
-
is it expected for relocation/recovery jobs to take a very long time, or get stuck?
-
is it expected a cluster can have two masters?
-
should I file a bug?

I'd appreciate any guidance on this, including pointers into ES code. Details -
-
0.20.6
-
6 data non master eligible nodes, m1.xlarge, Xms/Xmx 8G, Xmn 400M
-
3 master eligible nodes, non data nodes, m1.medium, 2G heaps
-
minimum master nodes: 2
-
ec2 discovery
Bill
--
You received this message because you are subscribed to the Google Groups "elasticsearch" group.
To unsubscribe from this group and stop receiving emails from it, send an email to elasticsearch+unsubscribe@googlegroups.com.
For more options, visit https://groups.google.com/groups/opt_out.
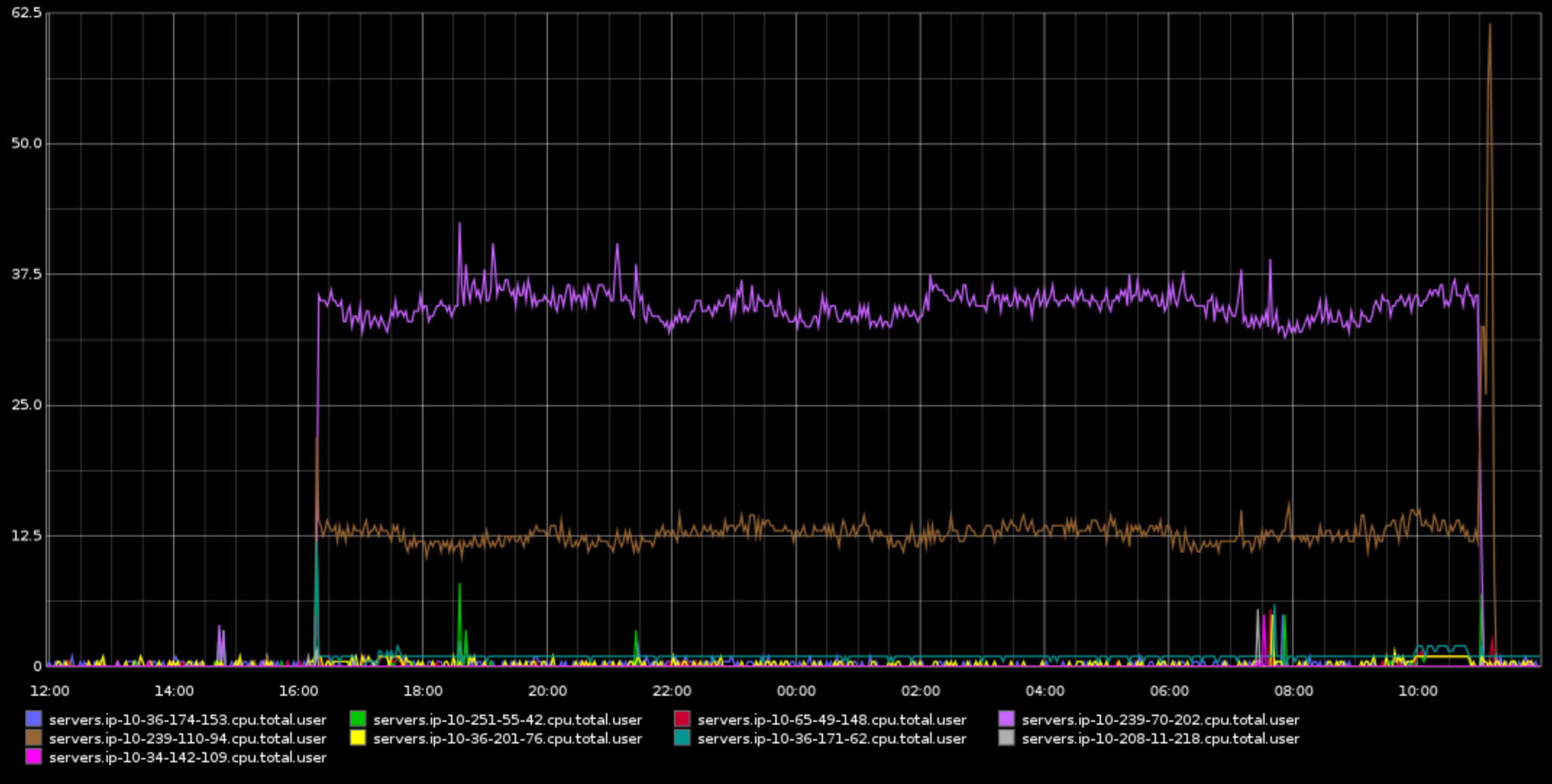{kind=link}