Can you post the error messages of your problem? What do you mean by "crash", an Out of Memory?
Hi, by crash I mean those gaps:
During this time, I have errors from Logstash telling me that Elasticsearch is unreachable.
In the elasticsearch I have the following error every time the Transform try to start:
[object_transform] Search context missing, falling back to normal search; request [apply_results]
org.elasticsearch.action.search.SearchPhaseExecutionException: all shards failed
The result is that the Transform can't work (the trigger count doesn't increase) and Elasticsearch is not available for few minutes (stopping Logstash by the same occasion).
Are Logstash and Elasticsearch run on the same machine?
Yes on the same machine, the version is 8.1.2 for all, and the machine is a centos7 with 32gb of Ram, the JVM is at 16GB.
Can you post some more details about the pipeline and your transform?
Filebeat is listening to a folder, I drop 55 files (total size 10GB) with a mv command.
A Logstash pipeline is running, like this one:
https://www.elastic.co/guide/en/logstash/current/pipeline-to-pipeline.html#distributor-pattern
There is a Grok pattern who parse my logs (extension .log), with a bit of Ruby code and Logstash filter.
A template is in Elasticsearch and change the mapping of those logs (keep only the "keyword", reduce the "ignore above" and use the date_nanos on my timestamp).
About the Transform, I do a lot of things there. It's continuous (I try 5 / 10 / 20 mins but the problem is always there). It uses a Pivot followed by 4 group by. I also added few bucket-script in order to calculate the duration of few events (substracting timestamps), nothing with runtime field, only information already present in the logs.
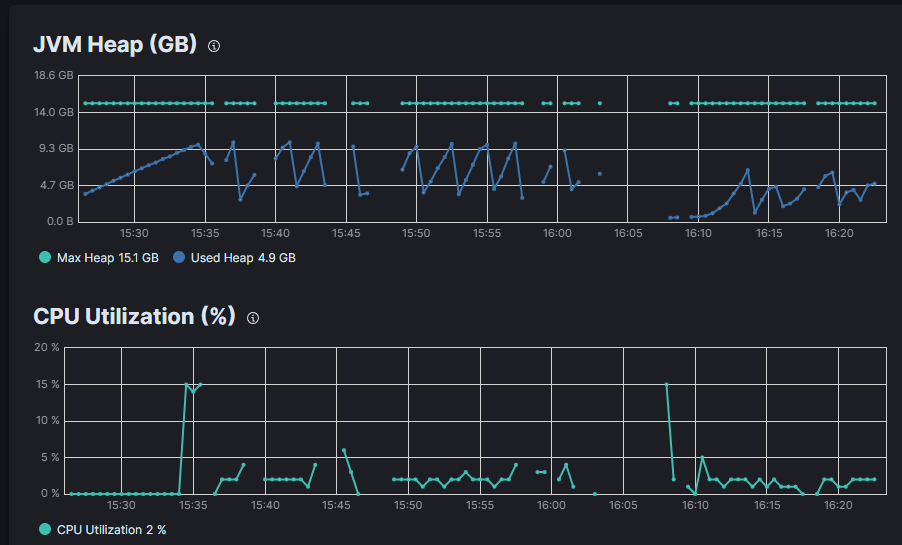
About the memory use
The ingestion alone use around 20% ram and the JVM around half. It works well and need 30 mins.
The transform alone use around 7% ram and the JVM around half. It works well and need 15 mins.
Together, this is the end, the ram is around 5% and it doesn't progress.
Given the current information it is not possible to answer your question.
Tell me if you need anything else