I work for a telco company and we are currently reporting on tests done by the technician at the customers location
I have currently a graph showing the count on all tests in total (off course with some filters applied e.g. to count the failed tests) but I received a request to only take into account the last test performed
(It is possible that a technician performs multiple tests at a customers premises and the requestor is only interested in the result of the last test)
I have a field to identify the customer (line number) but haven't been able to find a way to extract only the last result for all customers
What does the data look like in your documents? Does a test consist of a single document, or do documents need to be correlated together based on a test ID to track a single test?
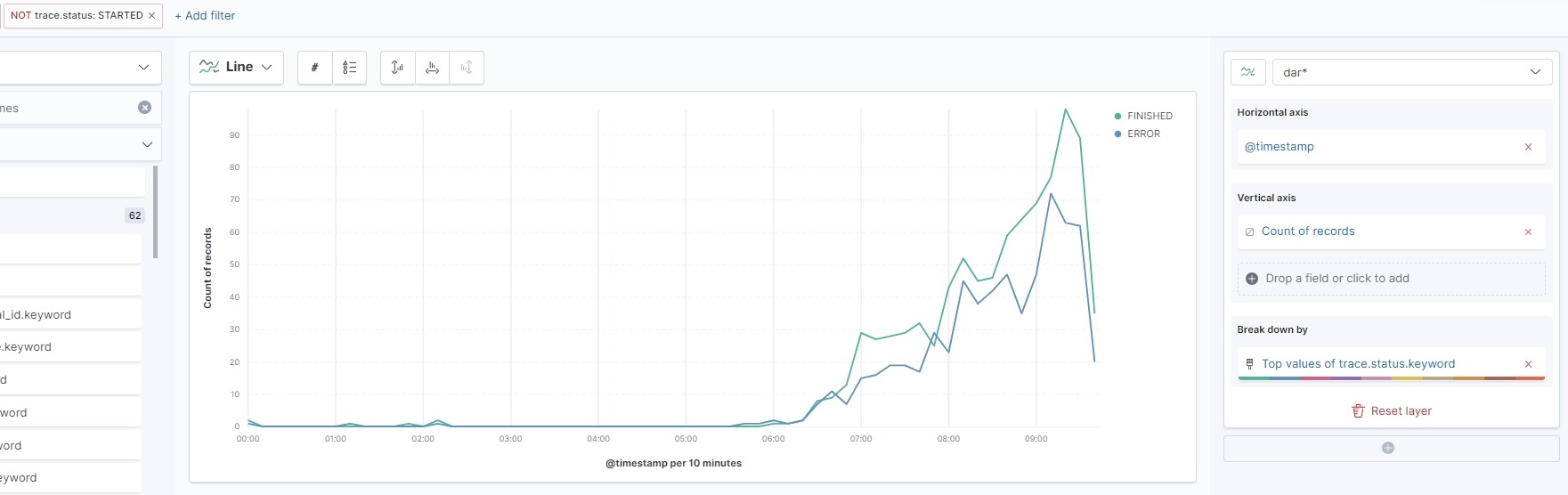
Can you provide a screenshot or sketch of: "graph showing the count on all tests in total". Is this aggregated by customer and timestamp?
basically a test can have 3 statuses: started, finished and error
I exclude the status started as I am only interested in the result of the test (finished is OK, error is obviously NOK)
A technician does multiple tests because the test actually indicates what's wrong with the installation and helps him to troubleshoot
So in fact the result of the last test is the most important because if that last test is not ok it means the customers installation is not ok when the technician left the customers premises
Every test is a single document, parsing has been applied and 2 fields are important
trace.status: this field contains the status of the test (I need to filter only on "finished" and "error")
trace.biq.dn: this field contains a unique identifier for the customer
so there can be multiple documents (tests) with the same trace.biq.dn but I am only interested in the most recent one for every unique trace.biq.dn
It sounds like you don't have a field in your data to distinguish tests clearly, such as an incrementing number. You'll probably want to have a transform in your data to group the related customer test documents together, take the latest one and copy it to a new index.
You can use the "latest" transform type of transform to do this. When you analyze the tranform index, you have the advantage of working only with the latest test for each customer.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.