I am new to Elasticsearch. I am trying to create a reporting application with Elastic search as Data Store. I get Input files, try and index it into ES via Logstash, and search / filter in ES for report output. The Issue I'm facing is, the data loading is very slow. (10k docs per minute where as in some tutorials i saw 20k apache docs per second) Obviosly im missing something here and kindly help me catch up and make the processing faster.
My system is of 8 GB RAM and 4 core processor. JVM Heap configured to 2GB for both Logstash & ES. The input file contains 30 Mil docs (Pipe seperated) and of 3.5 GB file size.Data is getting loaded to default 5 shards. It uses 4 workers(Got it with the use of metrics). The Logstash config is like the below one.
The speed improved to 12,000 docs per minute from 10,000 docs per minute. Not that much of an impact by removing stdout. Is there any other major thing I'm missing out here ?
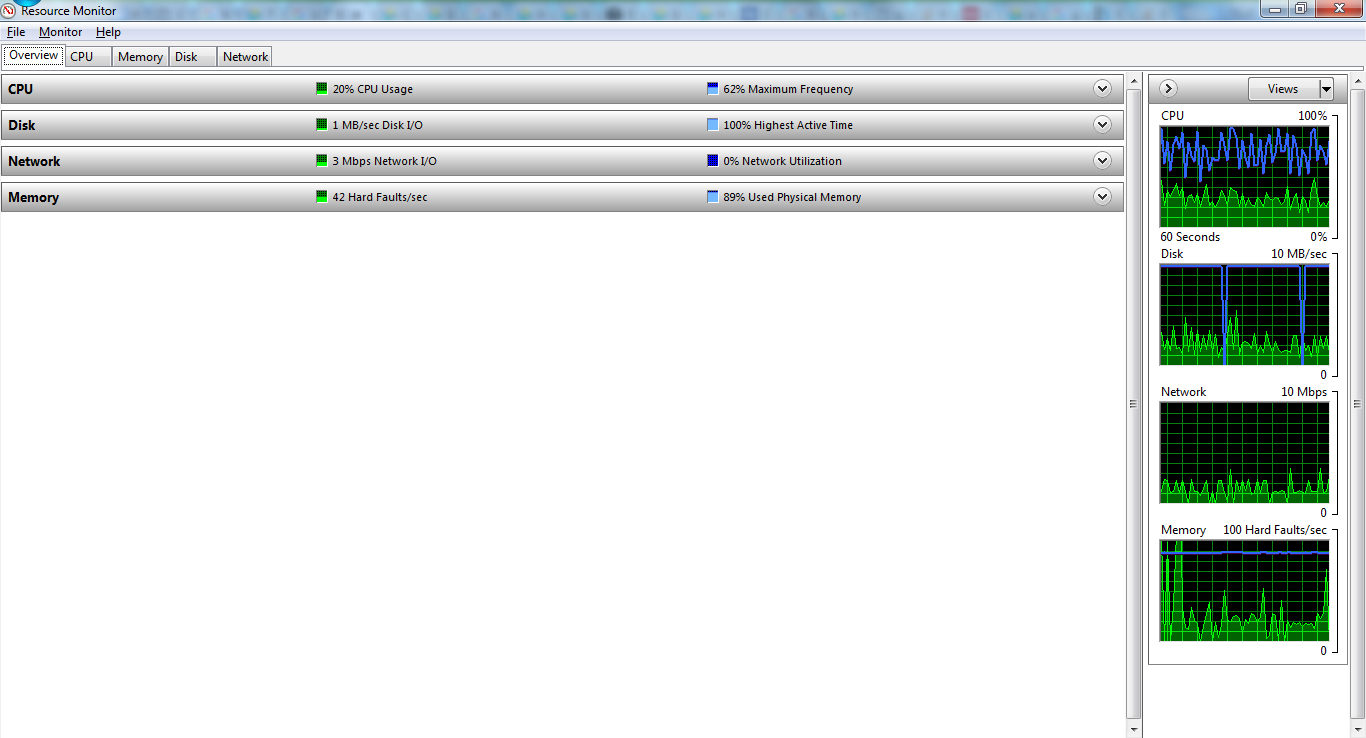
Which version of Elasticsearch and Logstash are you using? What is the average size of a record? What is resource utilisation looking like on the node during indexing, specifically around CPU usage and disk IO?
Do you mean to say that the Disk IO rate for the machine is slow which inturn affects the ES performance ? If that is so, I am able to load a tad faster in SSIS ETL tool by Microsoft in the very same machine. (1 million records in 3.5 mins)
Is the SQL Server database also on your laptop? Have you increased the refresh interval on the index you are indexing into? You can also try to increase the pipeline batch-size, e.g. to 1000, to see if this makes a difference.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.