Environment:
ES version: 5.3
Data nodes: 3
We are trying to, through elasticsearch, provide users pregenerated suggestions based on the current dataset (130M documents). The target is to get all unique values of a certain field's property in a certain search. Let's say Field.Name.untouched.
Here is the query:
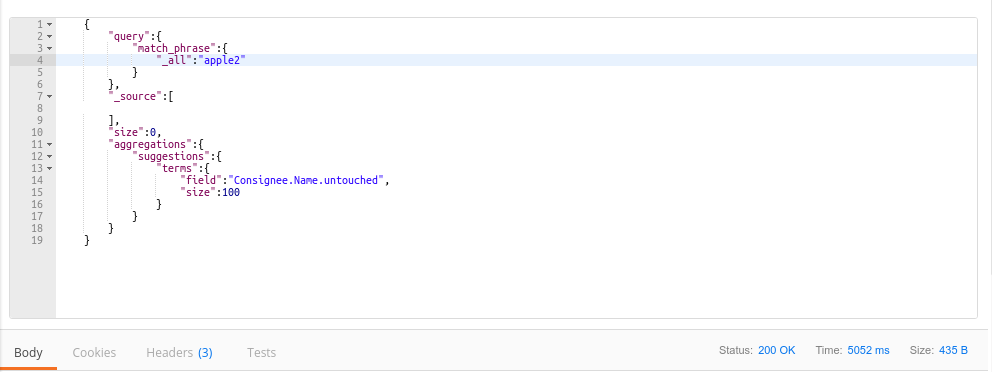
{
"query":{
"match_phrase":{
"_all":"tilapia"
}
},
"_source":[
],
"size":0,
"aggregations":{
"suggestions":{
"terms":{
"field":"Field.Name.untouched",
"size":100
}
}
}
}
Which, on its own, takes around 4 seconds. Since the query only takes unique values with no additional processing done, shouldn't it take less time than this? For reference, the retrieved values have a total of 124019 documents, which is not really much. Additionally, it seems that the query time is consistently near 5 seconds regardless of the number of results which is weird. For reference, I tried an absurd keyword which only shows up twice (apple2) but it also took around 4 seconds.
Is there something wrong with our query?
P.S. I don't know if this is relevant to the problem but by removing the aggregation part, the search query takes around 200 and 300 ms which makes the 4-5s query time a lot weirder in my point of view.