We need to do a lot of (front) wildcard queries on certain fields. One such field is url.original. Currently this is mapped in ECS as keyword. I'm wondering if this could be changed to wildcard field type?
For example we need to exclude all firewall logs where url.original ends with url.original: *.cedexis-test.com/. I've never used the wildcard field type, but would it be better if we update the mapping to wildcard in such a case to increase performance?
Roughly speaking leading infix queries (leading wildcard or .foo. regexes) have costs as follows:
keyword fields are linear with the number of unique terms
wildcard fields are linear with the number of docs that use a term
So if your URLs e.g. the site home page appear in many docs these are likely to be slow to match.
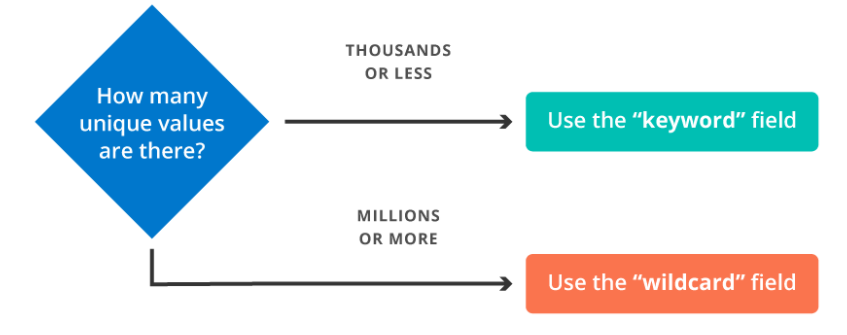
The flowchart at the end of this blog has a good decision chart.
Does the above unique values mean total unique values for url.orginal or total possible unique values for all possible results when using *.cedexis-test.com/
I think there are around 1000 unique *.cedexis-test.com/ in my data, so in that case a keyword would be my best option. But I have 100K+ unique url.original values so than a wildcard would be the best option.
total unique values for url.orginal or total possible unique values for all possible results when using *.cedexis-test.com/
The former.
The thing about prefix/infix queries and keyword fields is the index is of limited use to you.
Unlike an exact-match query or leading wildcard, the alphabetic sorting of the list of unique terms can't be used to quickly seek to the relevant part - infix/prefix queries have to scan the full list of all unique terms.
With URLs I imagine while there's a lot of unique values they're not evenly divided. So quite "Zipfy" e.g. a handful of URLs account for 90% of all mentions. These very popular URLs will be slow to query with wildcard field because it has to verify each use of a term in a doc whereas keyword fields need only find the term in the index and be certain all docs listed with that term genuinely do have that term.
Benchmarking is the only way to know for sure which is the best approach as so much depends on your data.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.