I did some significant maintenance on my cluster, changed from ES 1.6.0 to ES 1.7.1 and also changed from JVM 1.7 to 1.8. This is 13 nodes with 11TB of log data.
My plan was to shut off all the nodes and bring them all up. A rolling restart seemed like a lot of work, and would take longer, than a down and up across all nodes. I issued a persistent allocation freeze so nodes coming up would not automatically rebalance:
curl -XPUT localhost:9200/_cluster/settings -d '{
"persistent" : {
"cluster.routing.allocation.disable_allocation": true,
"cluster.routing.allocation.enable" : "none",
"cluster.routing.allocation.disable_replica_allocation": true,
"indices.recovery.concurrent_streams": 5,
"indices.recovery.max_bytes_per_sec": "100MB"
}
}'
Then I issued a shutdown:
curl -XPOST 'http://localhost:9200/_shutdown'
I waited for all the hosts to go down then I ran my updated chef scripts on all the nodes and brought them all up. They found eachother and I'm waiting for them to figure out all their shard data.
And now I'm staring as kopf reads
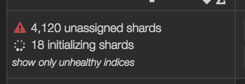
Some of the nodes are pegged at very high load and I have new nodes I want to introduce to the cluster but I will wait until things are settled.
At the very least I can turn on logstash again and continue ingesting data while all this settles down. May take half a day for the cluster to be "happy". At a rate of about 90 shards every 5 minutes. Is this a normal amount of time? Should I have gone for the rolling update? Should I tweak any other parameters or take out my tunings?
Also, how the heck do I set persistent values back to their default so they don't litter the curl -XGET localhost:9200/_cluster/settings?pretty=true output?