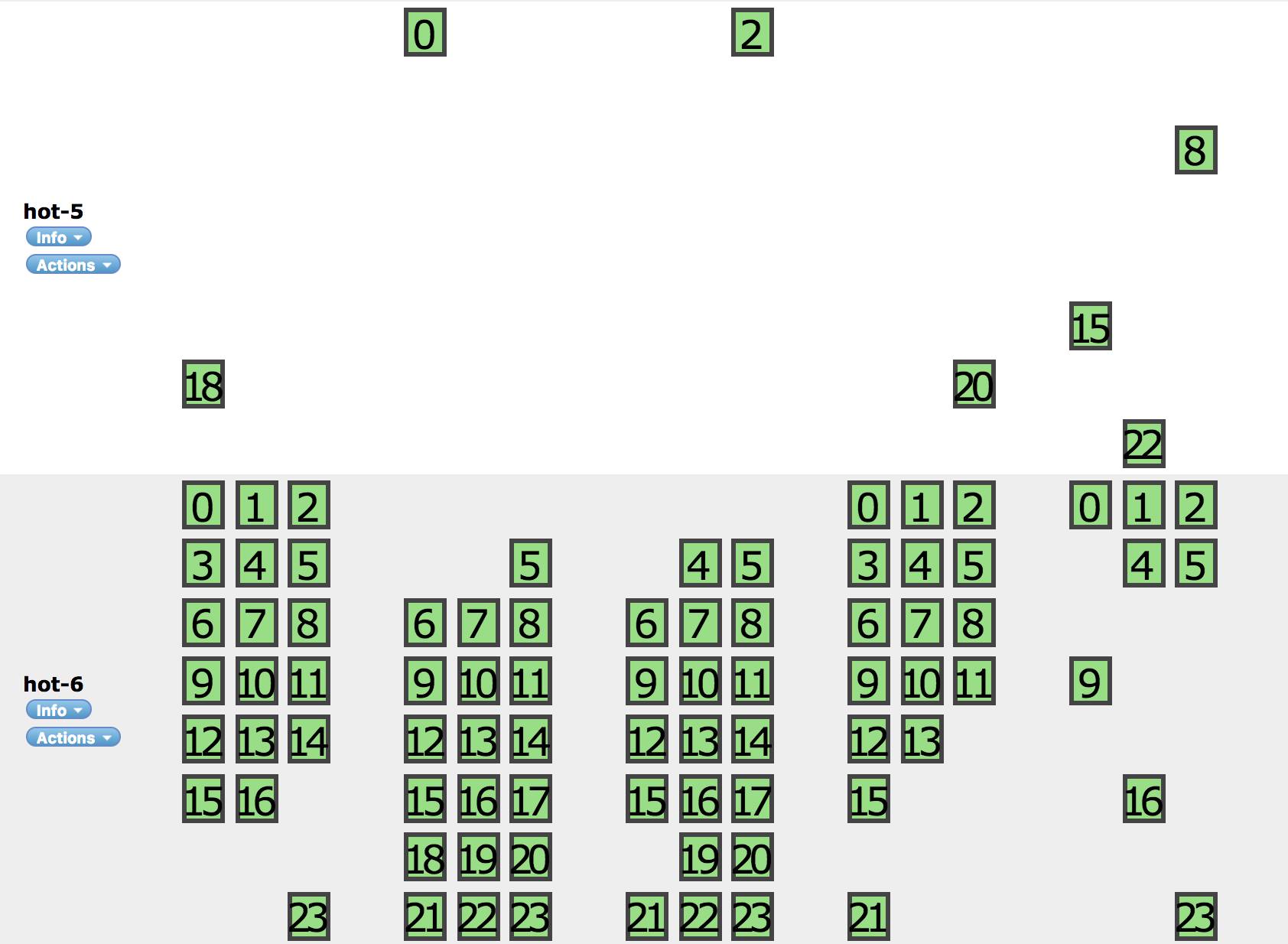
We're using Elasticsearch for almost our products and we found a strange issue on our Elasticsearch cluster.
The problem is that the shards are crowded in a node for a couple of indexes.
We've used that 5 data nodes and then recently, we've added 2 data nodes in the clusters.
After then, the shards are crowded in a 6th node.
Reproduce Issue
I can't say that how to reproduce this issue because other indexes are looking good.
Obviously, if we created new indexes then it could occur this issue.
Workaround
I believe we can resolve this issue if we can relocate the shards manually.
But I worried about occur again after doing that.
Questions
So, my questions are,
Is this a reasonable issue if the additional data nodes are added in exists cluster?
Is Elasticsearch performance still good if the shards are crowded in a single node?
If this topic could be an issue, how do we fix it?
cluster.routing.allocation.disk.watermark.low
Controls the low watermark for disk usage. It defaults to 85%, meaning ES will not allocate new shards to nodes once they have more than 85% disk used. It can also be set to an absolute byte value (like 500mb) to prevent ES from allocating shards if less than the configured amount of space is available.
Hm... If you theory is correct, then the 6th nodes should be not allocated new shards, but it's not.
But it's useful information for me. I didn't know this option, so that would be usable future version.
Thanks a lot!
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.