Example: I'm in charge of monitoring our infrastructure. I want to get the Requests per second, per core on a cluster. We have 5 clusters, each cluster has 5 servers in it, all reporting back system metrics once a minute, at XX:XX:50.000. One of these metrics is system.cpu.cores. I have a query to get the number of unique hosts, which I multiply by the number of cores on those machines(each system in a cluster should have the same number of cores)
To get the number of cores:
.es(index=beats-*,
q='fields.cluster.keyword:CLUSTER01 AND system.load.cores:*',
split="fields.cluster.keyword:1",
kibana=true,
metric="max:system.load.cores")
.fit(carry).aggregate(max)
This shows a solid line at 4.0 ( the expected number of cores) for any time period over 1 minute(where the metrics are guaranteed to have reported in at least once). This works fine until I zoom in a time period(under 59 seconds) at which point the graph completely disappears.
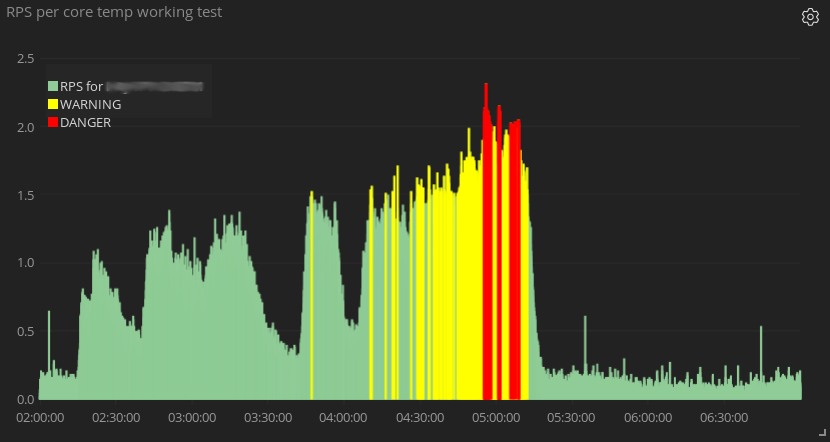
Using .value(4) gives me the same line, but it doesn't disappear under 59 seconds, and is what I want, but the number of cores for any given host isn't always 4. I think what I would want is to take the aggregate(max) of number of cores, and put it as a static value, so I can divide the number of requests per second by the number of cores to have accurate RPS per core at any given time
This is causing problems because while the RPS may be accurate for larger periods of time, when zooming it it can give completely wrong info.
For example, in some cases the RPS may be 100 for a cluster. That cluster has 5 machines, and each machine has 5 cores. So to get the RPSPC, I use the following:
.es(index=apache2-*,
q='fields.cluster.keyword:CLUSTER01 AND NOT error.type:*',
split="fields.cluster.keyword:1",
kibana=true)
.label("RPS for $1", "^.* > fields.cluster.keyword:(.+) > .*")
.divide(
.es(index=beats-*,
q='fields.cluster.keyword:CLUSTER01 AND system.load.cores:*',
split="fields.cluster.keyword:1",
kibana=true,
metric="max:system.load.cores")
.fit(carry))
.divide(
.es(index=apache2-*,
q='fields.cluster.keyword:CLUSTER01',
metric=cardinality:fields.khostname.keyword,
kibana=true)
.aggregate(max))
.bars(3,false),
and I end up with 100/5(hosts) = 20(requests per host), 20/5(cores)= 4 requests per core per second. But if I zoom in too far, the cores aggregate is blank, which I guess causes timelion to skip that division, leaving me with 20 requests per second per core, because it doesn't take in cores at all.
Is there any easy solution to this? or way I can "stretch" the data out using some conditional logic with if's? I could tell the system metrics to report the cores every second, but that would lead to a 60x increase in documents...