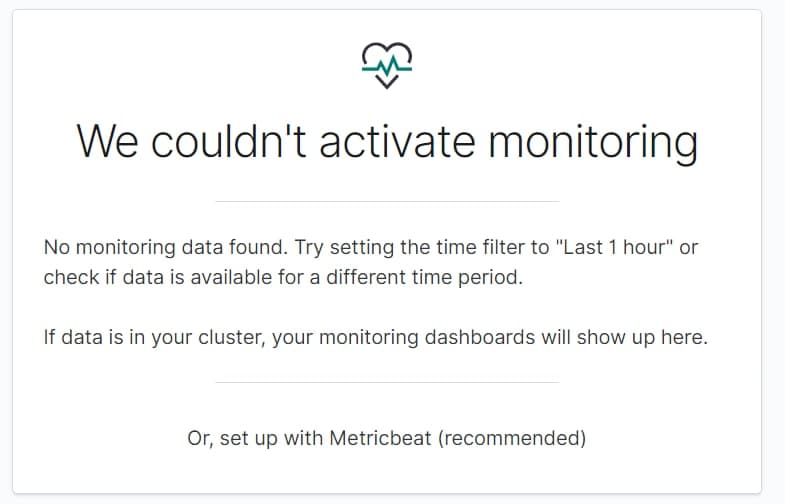
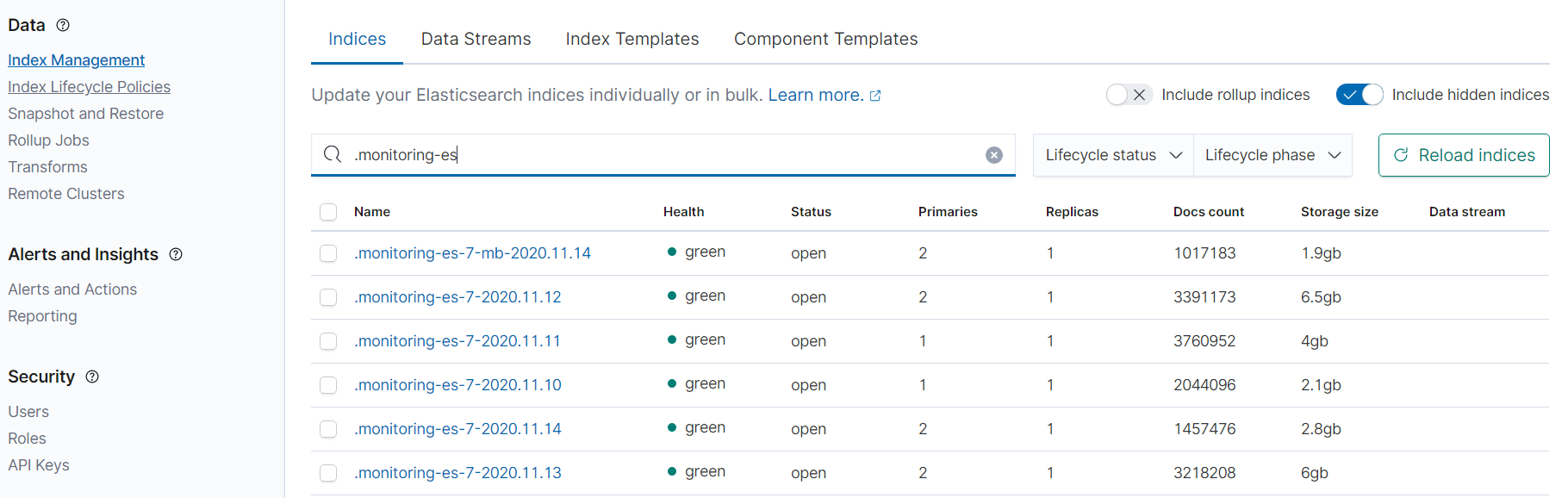
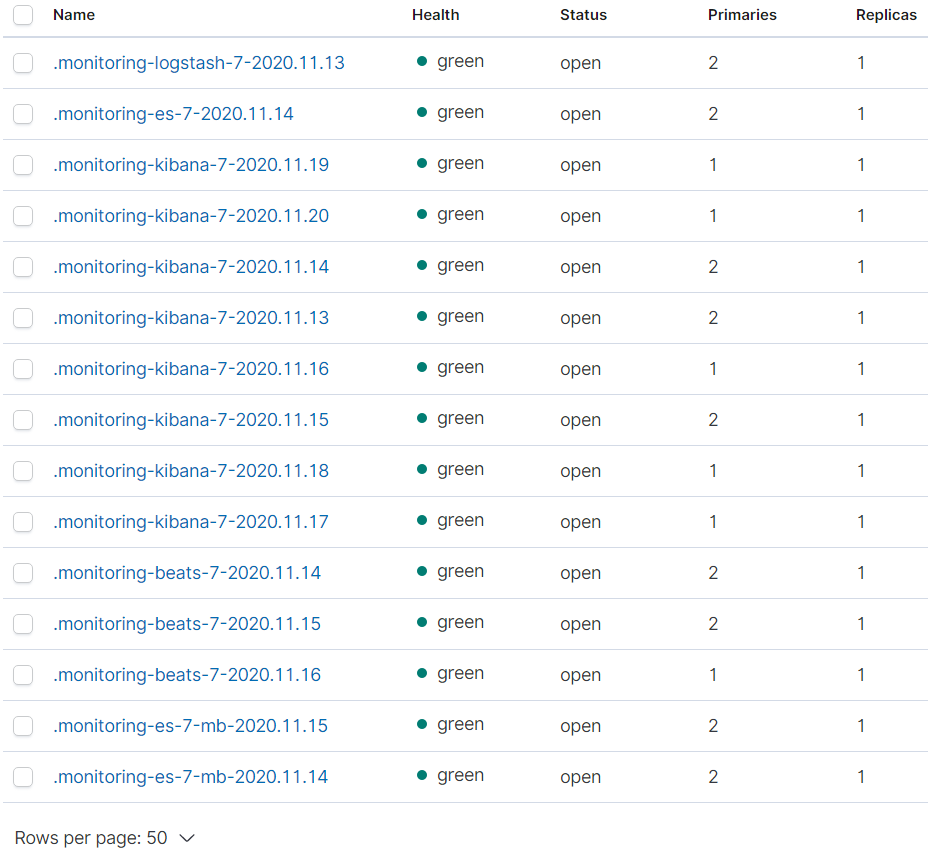
Я уже пробовал и через Metricbeat получать данные, но там такая же проблема, при этом индексы создаются и судя по их размеру информация в них в порядке. С местом проблем нет, данные в остальные индексы приходят. Если смотреть состояние кластера через Dev Tools, показывает что кластер зеленый. Свободные шарды есть. В логе /var/log/elasticsearch/cluster нет ошибок, ворнингов тоже.
Перед возникновением пробелмы вроде ничего не менял, кроме изменения политики Index Lifecycle Policy, но она вроде бы не должна влиять на доступность мониторинга.
ES и KIbana 7.9.1.
Уже третий день пытаюсь победить эту проблему, но ничего не получается. Подскажите пожауйста, с чем это может быть свзяано?
В самих индексах заметил что после попыток включить metricbeat, включить и выключить мониторинг, индексы мониторинга перестали создаваться. Создаются только индексы по мониторингу Kibana
При попытке поменять диапазон начинала появляться ошибка в правом нижнем углу:
Monitoring Request Failed
Unable to find the cluster in the selected time range. UUID: VdZPYWRCT8eMvjFOpWB6Lw
HTTP 404
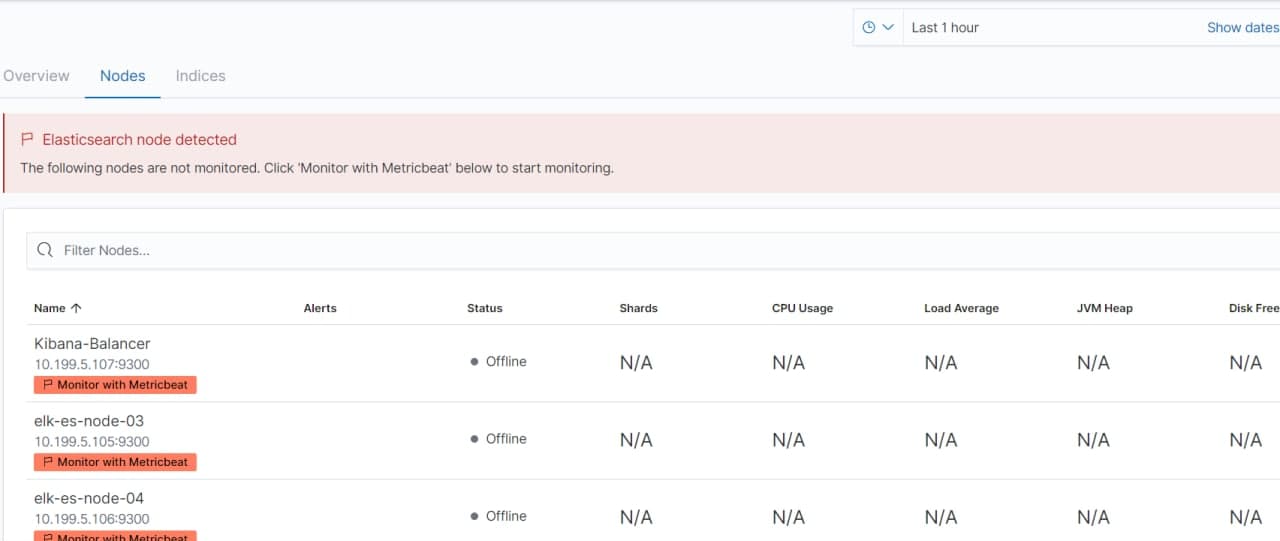
Но при этом состояние ноды можно было отследить в наличию IP-адреса. Если он был, значит нода активна, если нода перезагружалась, то в реальном времени адрес менялся на N/A и было видно что роль мастера переходит на другую ноду.
Сейчас при входе на эту страницу, независимо от выставленного диапазона, появляется вот такая ошибка
Monitoring Request Error
[illegal_argument_exception] unknown type for collapse field `cluster_uuid`, only keywords and numbers are accepted (and) [illegal_argument_exception] unknown type for collapse field `cluster_uuid`, only keywords and numbers are accepted (and) [illegal_argument_exception] unknown type for collapse field `cluster_uuid`, only keywords and numbers are accepted: Check the Elasticsearch Monitoring cluster network connection or the load level of the nodes.
HTTP 400
Выделенных нод нет, в логах только событие включения/выключения мониторинга.
Я попробовал отключить шифрование в кластере. После этого мониторинг стал работать, но только при нажатии на кнопку Setup with Metricbeat, при этом на странице появлялась ошибка
Monitoring Request Error
[illegal_argument_exception] Text fields are not optimised for operations that require per-document field data like aggregations and sorting, so these operations are disabled by default. Please use a keyword field instead. Alternatively, set fielddata=true on [logstash_stats.logstash.uuid] in order to load field data by uninverting the inverted index. Note that this can use significant memory.: Check the Elasticsearch Monitoring cluster network connection or the load level of the nodes.
HTTP 400
Я попробовал по совету из последней статьи поменять таймаут с 30 секунд на 15
PUT _cluster/settings
{
"persistent": {
"xpack.monitoring.collection.cluster.stats.timeout": "15s"
}
}
и после этого всё стало работать как раньше.
Относительно проблемы, которая была с мониторингом в первом посте, я подумал что может быть это как-то связано с тем что у меня имя ноды-координатора и кибаны, которые находятся на одном хосте, совпадают. Хочу попробовать поменять имена и настроить шифрование ещё раз.
Т.е. он у вас был выставлен на 30с до этого? Звучит странно, т.к. вы уменьшили его в этом случае. У параметра 10с по умолчанию, его повышение с 10 до 15 звучит логично для разрешения проблемы.
Если все так и было (повышение с дефолтных 10 до 15с решило проблему) - признак того что ваш мастер перегружен. Советую перейти на выделенные мастер ноды.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.