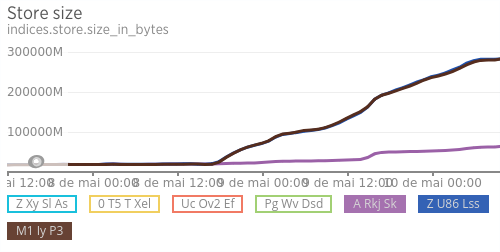
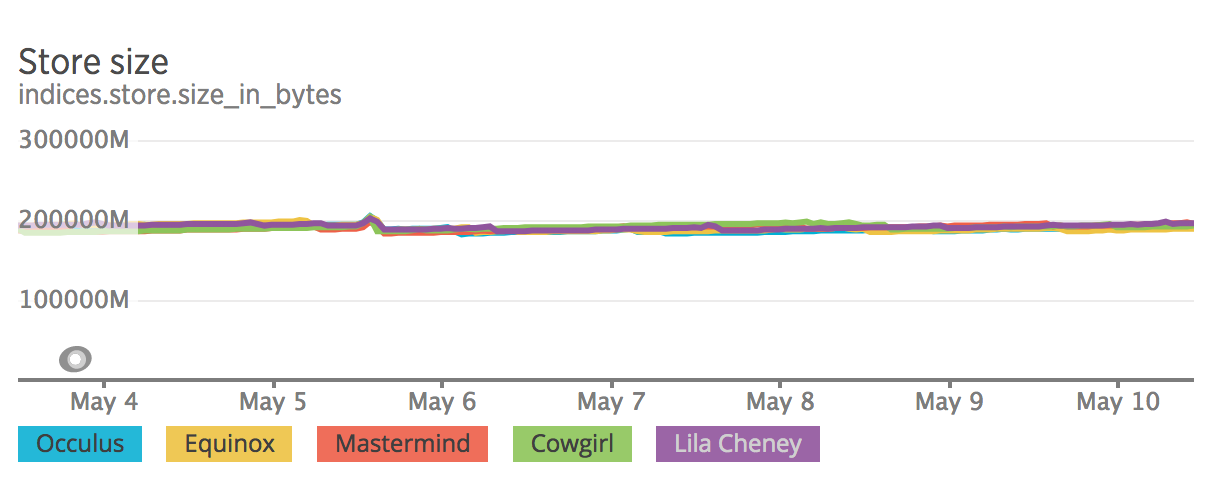
On a 5 node cluster, the shards are balanced, but the disk space used is unbalanced. Checking the directories, I found that the shards are taking around 10 times the size of the shard on the disk.
//tickets_v2 2 p STARTED 1688677 30.5gb 10.14.23.210 Occulus
tickets_v2 2 r STARTED 1688677 28.9gb 10.14.66.191 Lila Cheney
tickets_v2 4 p STARTED 1690046 34.6gb 10.14.66.191 Lila Cheney
tickets_v2 4 r STARTED 1690046 30.1gb 10.14.17.10 Equinox
tickets_v2 1 r STARTED 1687292 26.9gb 10.14.23.210 Occulus
tickets_v2 1 p STARTED 1687292 30.1gb 10.14.23.34 Cowgirl
tickets_v2 3 p STARTED 1688535 31.3gb 10.14.65.216 Mastermind
tickets_v2 3 r STARTED 1688535 27.9gb 10.14.17.10 Equinox
tickets_v2 0 r STARTED 1688199 28.6gb 10.14.65.216 Mastermind
tickets_v2 0 p STARTED 1688198 30.2gb 10.14.23.34 Cowgirl
root@elasticsearch2:/data/elasticsearch/touch/nodes/0/indices/tickets_v2# du -sh *
299G 3
300G 4
8.0K _state
On the other node it is -
root@elasticsearch1:/data/elasticsearch/touch/nodes/0/indices/tickets_v2# du -sh *
28G 1
302G 2
8.0K _state
Why would this be? and any solutions to this ?
@Christian_Dahlqvist : Shall I flush it with (POST /tickets_v2/_flush) ? What will be its effect on the application? Would the other indices continue to serve ?
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.