Hi!
I have an elastic cluster -
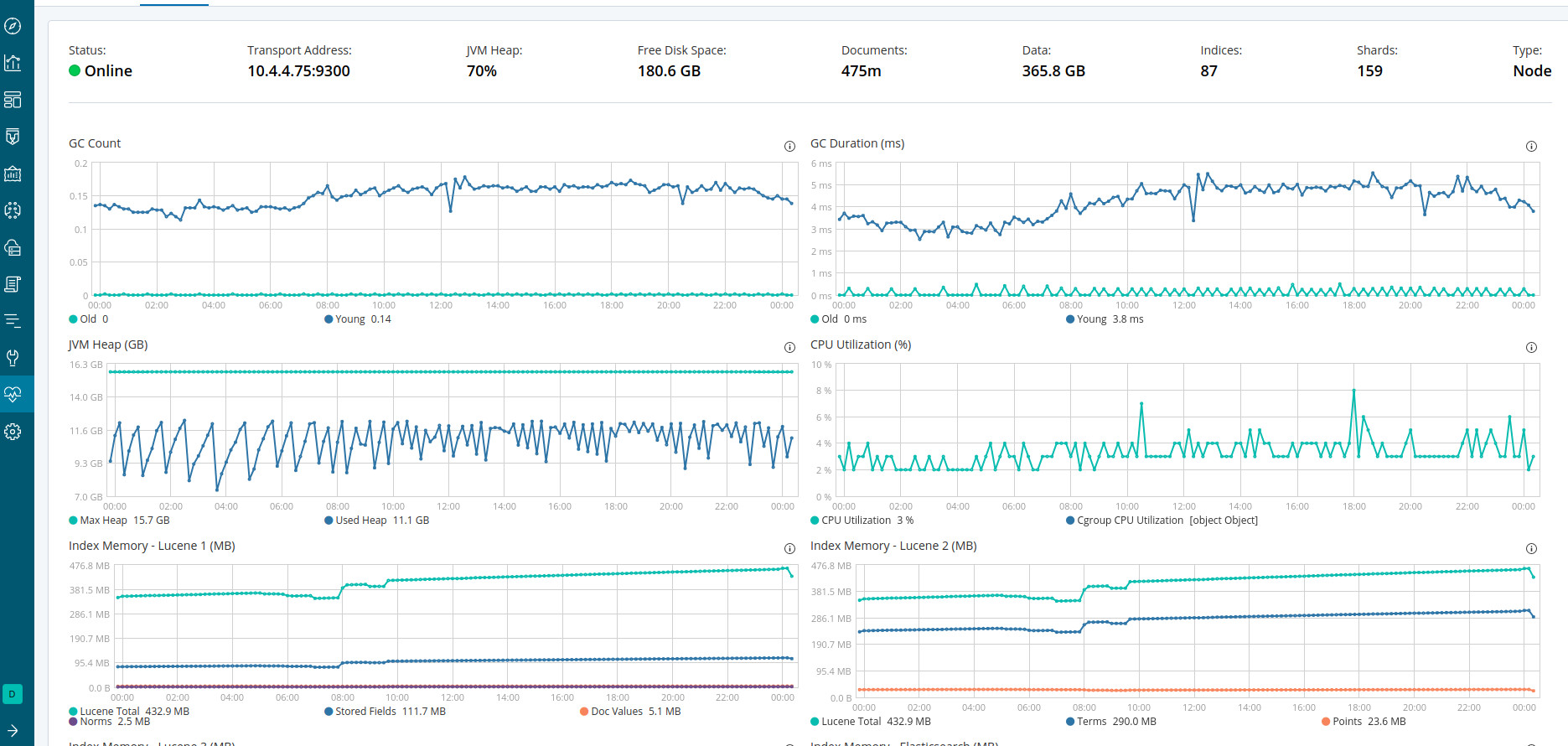
1 dedicated master node with 1GB of heap
6 data nodes ( 32 cpu, 31GB heap and about 100GB more for file cache; disk and network io utilization is 5% on all data nodes)
I have two main indices that I'm writing to using filebeat and logstash.
xvd_logs - 120 million documents per day and 300GB of data
{
"index_patterns": ["xvd_logs-*"],
"settings": {
"number_of_shards": 12,
"index": {
"refresh_interval": "10s"}},
wsk_log - 60 million documents per day and 60GB of data
{"order": 1,
"index_patterns": [
"wsk_log-*"
],
"settings": {
"index": {
"highlight": {
"max_analyzed_offset": "30000000"
},
"mapping": {
"total_fields": {
"limit": "10000"
}
},
"refresh_interval": "30s",
"number_of_shards": "12",
"merge": {
"scheduler": {
"max_thread_count": "1"}}}},
Both of these have static mappings that i've set in templates
Bulk indexing writes are piling up on all hosts at the same time. They pile up for 10-30 minutes and then all get indexed at the same time. Then cluster works normally for a few minutes.
curl -s --noproxy "*" -X GET "http://elastic:9200/_cat/tasks?detailed&v" | wc -l
1363
action task_id parent_task_id type start_time timestamp running_time ip node description
indices:data/write/bulk Jffd7IX0RCa-UR228cW2Xw:18951228 - transport 1552583715789 17:15:15 6.7m 10.4.4.75 node3 requests[4096], indices[wsk_log-2019.03.14]
indices:data/write/bulk[s] Jffd7IX0RCa-UR228cW2Xw:18951231 Jffd7IX0RCa-UR228cW2Xw:18951228 transport 1552583715793 17:15:15 6.7m 10.4.4.75 node3 requests[354], index[wsk_log-2019.03.14]
indices:data/write/bulk[s] xt-LfJPdQPaO7uC-lX7TFw:17591898 Jffd7IX0RCa-UR228cW2Xw:18951231 netty 1552583715816 17:15:15 6.7m 10.100.100.105 node6 requests[354], index[wsk_log-2019.03.14]
indices:data/write/bulk[s][p] xt-LfJPdQPaO7uC-lX7TFw:17591899 xt-LfJPdQPaO7uC-lX7TFw:17591898 direct 1552583715816 17:15:15 6.7m 10.100.100.105 node6 requests[354], index[wsk_log-2019.03.14]
indices:data/write/bulk ODJXLTi6SiqylmA-7mi1dA:22685282 - transport 1552583716138 17:15:16 6.7m 10.4.4.67 node1 requests[4096], indices[wsk_log-2019.03.14]
indices:data/write/bulk[s] ODJXLTi6SiqylmA-7mi1dA:22685285 ODJXLTi6SiqylmA-7mi1dA:22685282 transport 1552583716147 17:15:16 6.7m 10.4.4.67 node1 requests[322], index[wsk_log-2019.03.14]
indices:data/write/bulk[s] xt-LfJPdQPaO7uC-lX7TFw:17591934 ODJXLTi6SiqylmA-7mi1dA:22685285 netty 1552583716162 17:15:16 6.7m 10.100.100.105 node6 requests[322], index[wsk_log-2019.03.14]
indices:data/write/bulk[s][p] xt-LfJPdQPaO7uC-lX7TFw:17591935 xt-LfJPdQPaO7uC-lX7TFw:17591934 direct 1552583716162 17:15:16 6.7m 10.100.100.105 node6 requests[322], index[wsk_log-2019.03.14]
indices:data/write/bulk Jffd7IX0RCa-UR228cW2Xw:18951289 - transport 1552583716156 17:15:16 6.7m 10.4.4.75 node3 requests[4096], indices[wsk_log-2019.03.14]
indices:data/write/bulk[s] Jffd7IX0RCa-UR228cW2Xw:18951292 Jffd7IX0RCa-UR228cW2Xw:18951289 transport 1552583716162 17:15:16 6.7m 10.4.4.75 node3 requests[351], index[wsk_log-2019.03.14]
indices:data/write/bulk[s] xt-LfJPdQPaO7uC-lX7TFw:17591938 Jffd7IX0RCa-UR228cW2Xw:18951292 netty 1552583716178 17:15:16 6.7m 10.100.100.105 node6 requests[351], index[wsk_log-2019.03.14]
indices:data/write/bulk[s][p] xt-LfJPdQPaO7uC-lX7TFw:17591939 xt-LfJPdQPaO7uC-lX7TFw:17591938 direct 1552583716178 17:15:16 6.7m 10.100.100.105 node6 requests[351], index[wsk_log-2019.03.14]
...
...
...
indices:data/write/bulk[s] Jffd7IX0RCa-UR228cW2Xw:18980372 Jffd7IX0RCa-UR228cW2Xw:18980363 transport 1552584122394 17:22:02 14.3ms 10.4.4.75 node3 requests[328], index[wsk_log-2019.03.14]
indices:data/write/bulk[s] Jffd7IX0RCa-UR228cW2Xw:18980374 Jffd7IX0RCa-UR228cW2Xw:18980363 transport 1552584122394 17:22:02 13.9ms 10.4.4.75 node3 requests[353], index[wsk_log-2019.03.14]
indices:data/write/bulk[s] Jffd7IX0RCa-UR228cW2Xw:18980375 Jffd7IX0RCa-UR228cW2Xw:18980363 transport 1552584122395 17:22:02 13.4ms 10.4.4.75 node3 requests[352], index[wsk_log-2019.03.14]
indices:data/write/bulk[s][p] Jffd7IX0RCa-UR228cW2Xw:18980377 Jffd7IX0RCa-UR228cW2Xw:18980375 direct 1552584122395 17:22:02 13.4ms 10.4.4.75 node3 requests[352], index[wsk_log-2019.03.14]
indices:data/write/bulk[s] Jffd7IX0RCa-UR228cW2Xw:18980376 Jffd7IX0RCa-UR228cW2Xw:18980363 transport 1552584122395 17:22:02 13.4ms 10.4.4.75 node3 requests[339], index[wsk_log-2019.03.14]
Filebeat logs have tons of "Timeout exceeded while awaiting headers" to all nodes:
|2019-03-14T19:29:27.164+0300|ERROR|pipeline/output.go:121|Failed to publish events: Post http://node3:9200/_bulk: net/http: request canceled (Client.Timeout exceeded while awaiting headers)|
|2019-03-14T20:00:23.654+0300|ERROR|elasticsearch/client.go:319|Failed to perform any bulk index operations: Post http://node2:9200/_bulk: net/http: request canceled (Client.Timeout exceeded while awaiting headers)|
|2019-03-14T20:00:24.949+0300|ERROR|pipeline/output.go:121|Failed to publish events: Post http://node1:9200/_bulk: net/http: request canceled (Client.Timeout exceeded while awaiting headers)|
filebeat monitoring page in kibana

I'm pretty sure that I caused it, because we want to write 2-3 times as many data next month, and i was playing around with different settings ( shard number, reshresh_interval, async translog, etc.). I reverted all obvious settings back but that didn't help ![]()