We have 4 ES machines running on AWS under a VPC behind an LB which are currently working without any issues.
We wanted to migrate these 4 ES machines from this older VPC to the newer VPC behind a new LB. So, we followed the following approach:
- Boot up 4 new machines from AMI inside new VPC.
- Ran our ansible scripts for setting up these 4 machines with ES and configuration as same as the old 4 machines.
- We've a huge number of indexes, i.e. date-wise indexes and an all data index. Each index has 12 primary and 12 replicas.
- Before adding we had 320 shards distributed in these old 4 machines. Making them 80 shards/machines. After adding these 4 new machines to the existing cluster. Making the shards' distribution to 40 shards/machines. Which is 8 machines in total at this point.
- We waited for shard re-allocation to complete.
- Once the cluster was green, we ran a sanity script to verify the health of the machines. All good until this point.
- Verified the production status. All green.
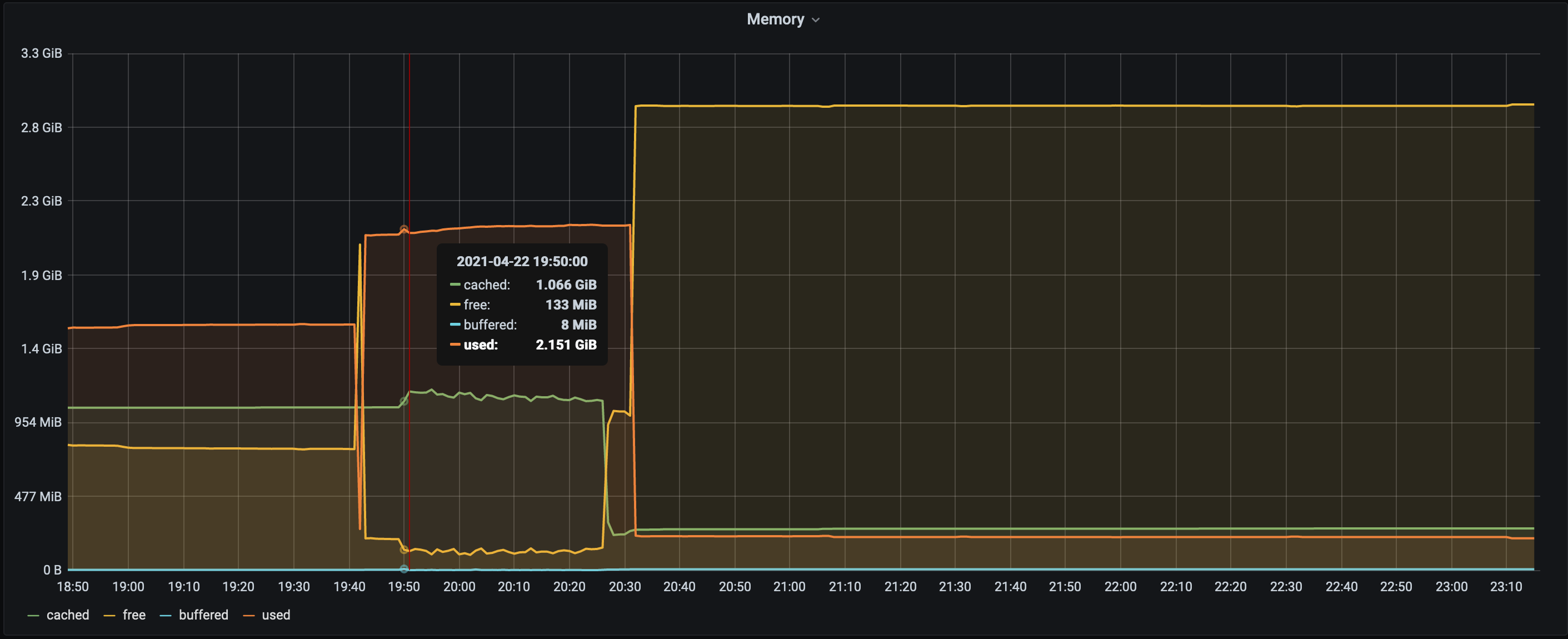
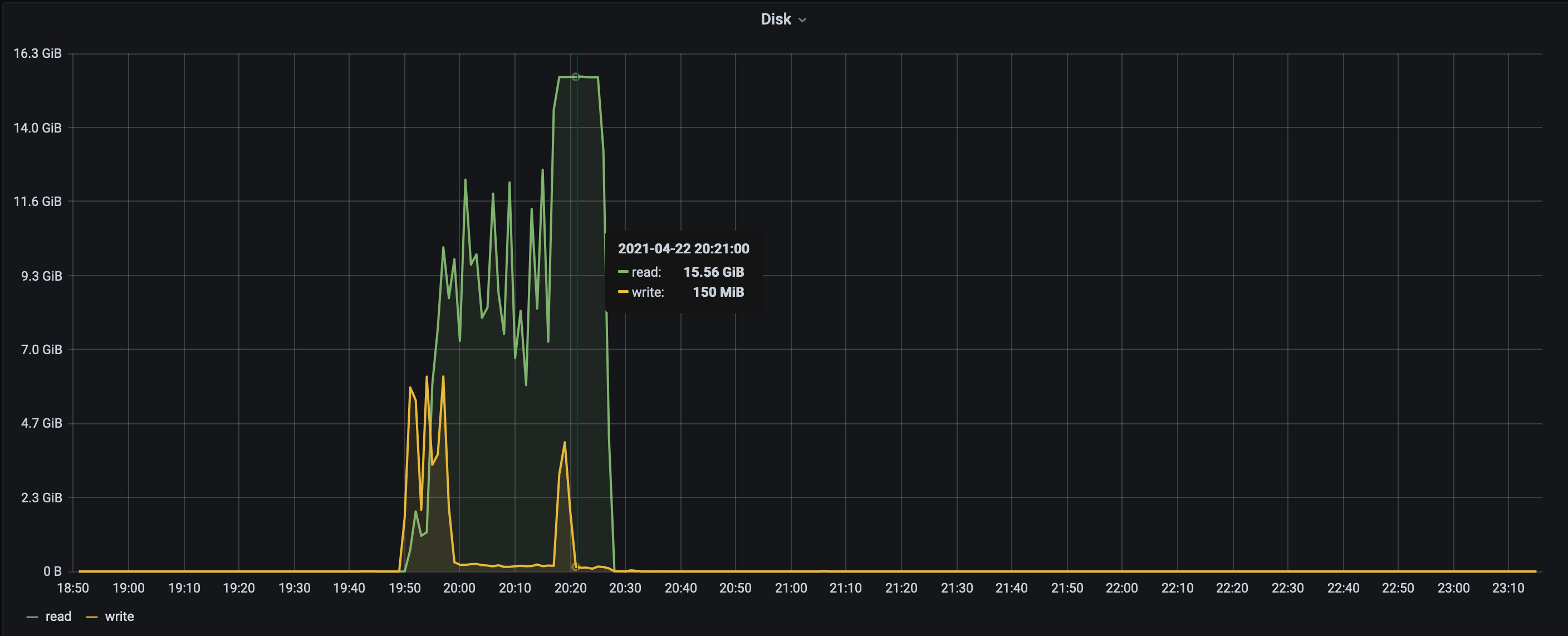
- We switch the Route53 entry from the old LB to point to the new LB and that's when 2 of the new machines started seeing disk read spikes(reads went up to 15 GB/s).