I just upgraded my cluster to 5.2 and in the process of moving some shards after restart one of the nodes just dies without any logs. The only thing I could find was this in syslog:
Feb 2 20:53:34 es-replicashard2 kernel: [896534.883938] Out of memory: Kill process 11816 (java) score 354 or sacrifice child
Feb 2 20:53:34 es-replicashard2 kernel: [896534.884353] Killed process 11816 (java) total-vm:805368608kB, anon-rss:31801460kB, file-rss:3147904kB
Feb 2 20:53:35 es-replicashard2 systemd[1]: elasticsearch.service: Main process exited, code=killed, status=9/KILL
Feb 2 20:53:35 es-replicashard2 systemd[1]: elasticsearch.service: Unit entered failed state.
Feb 2 20:53:35 es-replicashard2 systemd[1]: elasticsearch.service: Failed with result 'signal'.
I have around 3.6 billion documents. 8 nodes: 2 clients, 4 nodes master+data, 2 nodes just data. The memory for each node except the clients is 94GB with 28G heap size (also 14 core each). The settings for shards (allocations, transition, etc.) are the default. Also, each node has around 150-160 shards.
So my questions are:
What does this out of memory indicate? Is this the heap size cause it says (java) or the total of the memory for the machine?
Is there a limit in terms of memory for the number of shards that each node can handle? And if it's yes, how can I calculate the size of needed memory during shards transition after restart?
I haven't seen out of memory for shard transitions in my cluster since the beginning (0.9). I've seen out of memory for big search/aggregations though (before version 2.0). I've also seen performance impact when you have lots of shards on the node. But I think my nodes are big enough for a moderate inserts/updates of 40-50 million per day and 20k-30k query/aggs per day. Am I wrong on this?
I always look at the disk or performance for adding new node to the cluster. I never though during the shards relocation there is a memory usage that I have to take into account. Kinda like index building of MongoDB when it runs out of memory if the index is bigger that the machine memory.
PS: I removed about 400M documents (packetbeat) and started the node again. The cluster is green.
Update: The cluster was green but it happened again!
I rebooted all the servers. It's been stable ever since. So my best guess is the cache usage of the machines caused this Out of the Memory signal.
To my understanding the amount of cache (besides the heap size) can be taken away by the system when ever it needs it. Maybe there is a misunderstanding here of which memory (heap, non-heap) is being used for moving/rellocating shards around or how machine uses the memory in my KVM machines.
FYI:There is no ballooning nor over allocating of any resources. All the resources are being assigned dedicated.
You got bitten by the kernel OOM killer - this means that there is not a heap issue, but rather something else is eating your memory. Wild before-the-first-coffee assumption: You may have been bitten by https://issues.apache.org/jira/browse/LUCENE-7647 which will be fixed with the next 5.2 release. You can try by not using best_compression if this changes anything.
That was a very good catch! I had a quick look at the Lucene issue and it fits right into my problem. Although my problem only occurred once during cluster restart, it's good to know there is high chance this is a bug and not an architecture problem on my side.
Many thanks Alex, I'll keep you updated if this happens again especially in a new 5.2 release.
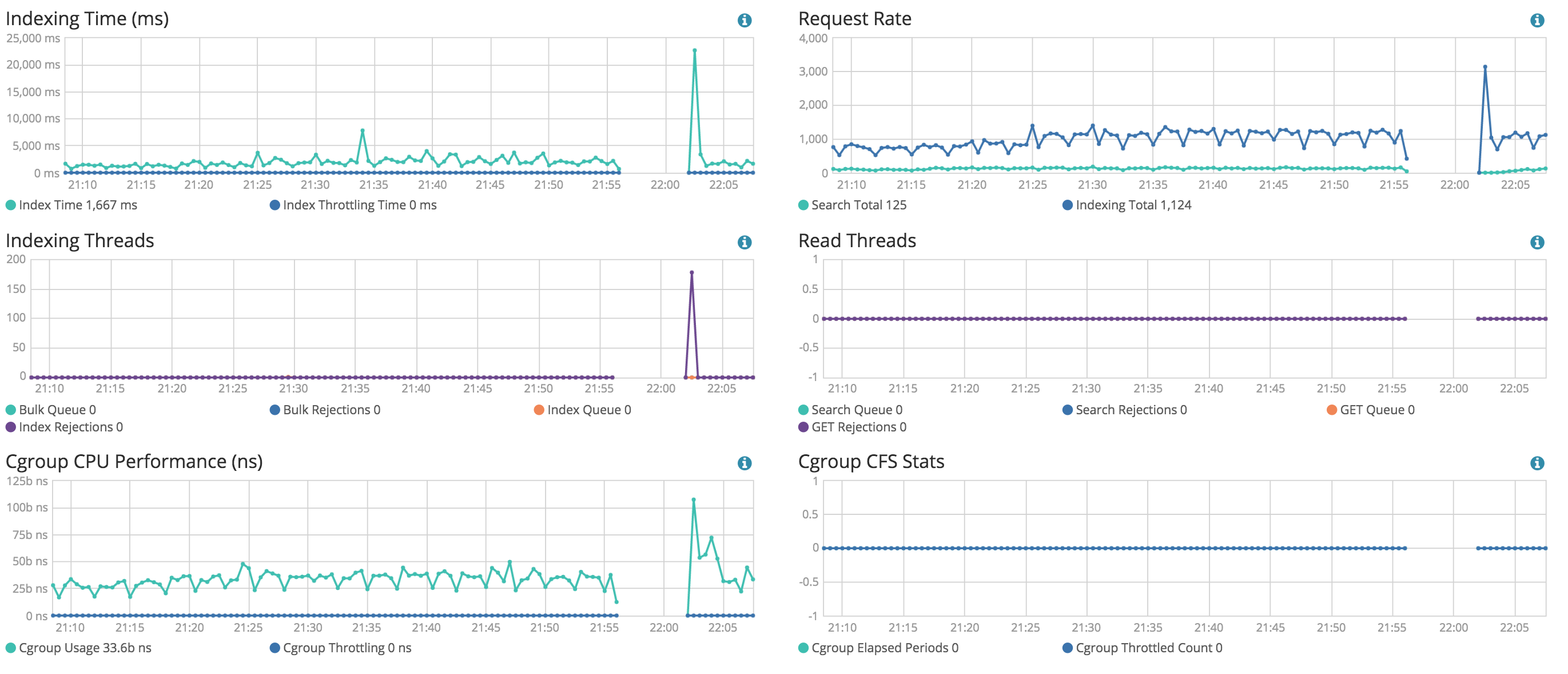
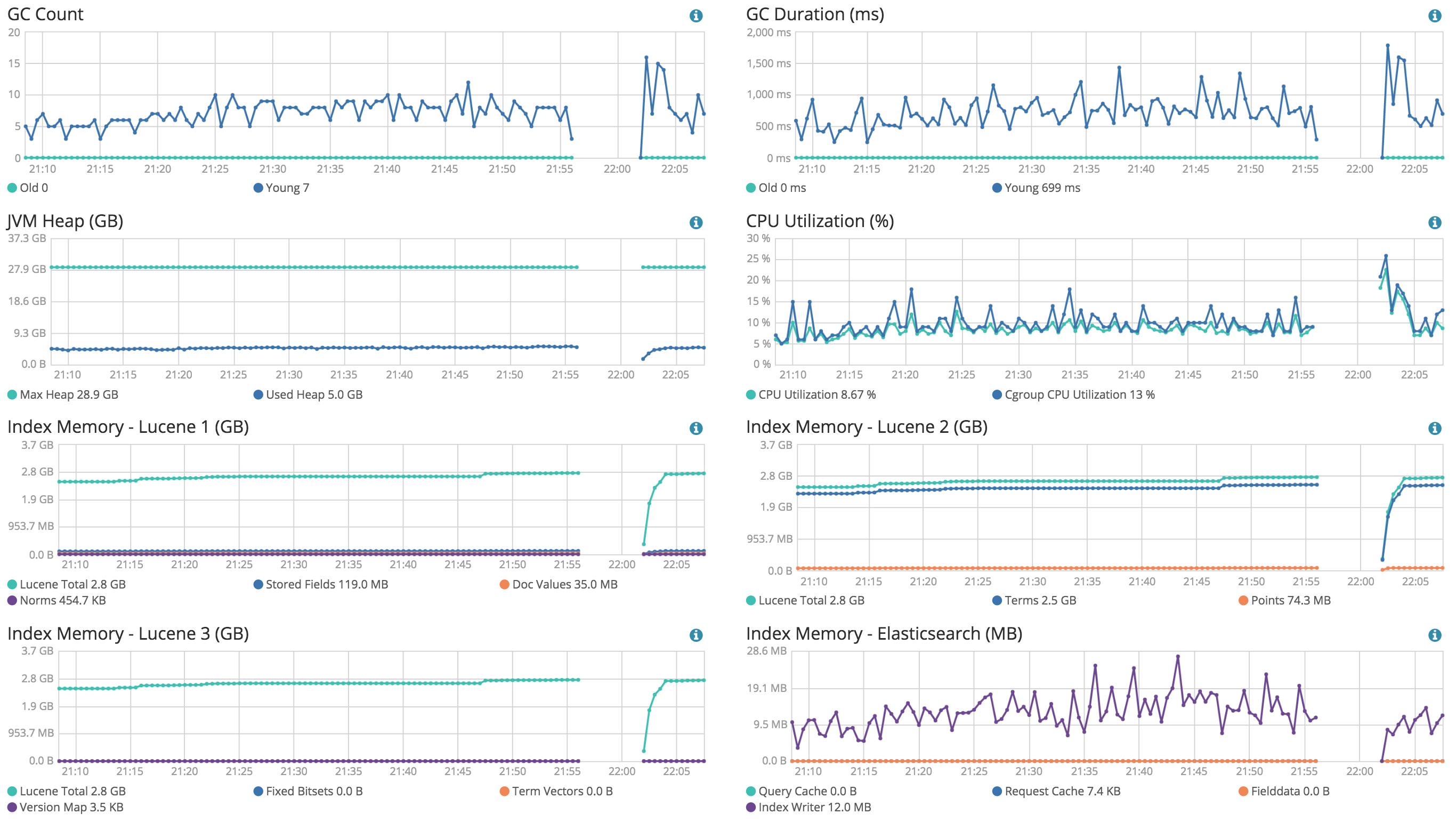
Ok last night I lost one of my nodes and the entire cluster went down for the exact same reason. But this time it wasn't after a cluster restart/shard initializations. It just happened after two weeks of uptime:
Feb 17 00:40:31 es-replicashard6 kernel: [1217848.272673] Out of memory: Kill process 1234 (java) score 409 or sacrifice child
Feb 17 00:40:31 es-replicashard6 kernel: [1217848.273309] Killed process 1234 (java) total-vm:916776296kB, anon-rss:33002496kB, file-rss:7359856kB
Feb 17 00:40:32 es-replicashard6 systemd[1]: elasticsearch.service: Main process exited, code=killed, status=9/KILL
Feb 17 00:40:32 es-replicashard6 systemd[1]: elasticsearch.service: Unit entered failed state.
Feb 17 00:40:32 es-replicashard6 systemd[1]: elasticsearch.service: Failed with result 'signal'.
I just upgraded to 5.2.1 and hoping this doesn't happen again.
Well that is not a good news for me! I thought the newer version of apache lucene in 5.2.2 would solve this problem.
But on a bright side, yours might be a different issue with the same symptoms .
I never believed that is a good idea to have ES cluster geo-distributed via VPN/SSH etc. But if you don't have any problem there that is fine. (queuing up the bulk and Ops maybe an overkill though)
Your amount of memory is a bit lower than I expected for an ES cluster but it depends on your load. Would you mind sharing some stats like number of inserts/updates/query per second?
My stats so far:
Uptime: 12 days (I had to restart the machines for some reason that I don't remember!)
Inserts/updates all shards: +60m per day
Queries: +3m per day
Total Shards: 1394
Indices: 305
So far I haven't had this problem and I hope it doesn't happen again cause it just destroys my entire architecture (my fault though, I got lazy to implement queue for all my apps!)
Ok that's some good stats. May I know the size of those documents? Also, how many shards/replica? The reason I am asking is, it may be 20/s but they can be huge or with so many fields that is using dynamic mappings.
I still think 2G heap size and 2G for the rest of the system+caching is not really enough for that size of data. One thing you can look at is after how many documents you'll get the out of memory signal. I imagine when the cluster is fresh with no documents, it won't result in out of memory.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.

 (my fault though, I got lazy to implement queue for all my apps!)
(my fault though, I got lazy to implement queue for all my apps!)