Here's my cluster, hosting on elastic.co:

My index activity:

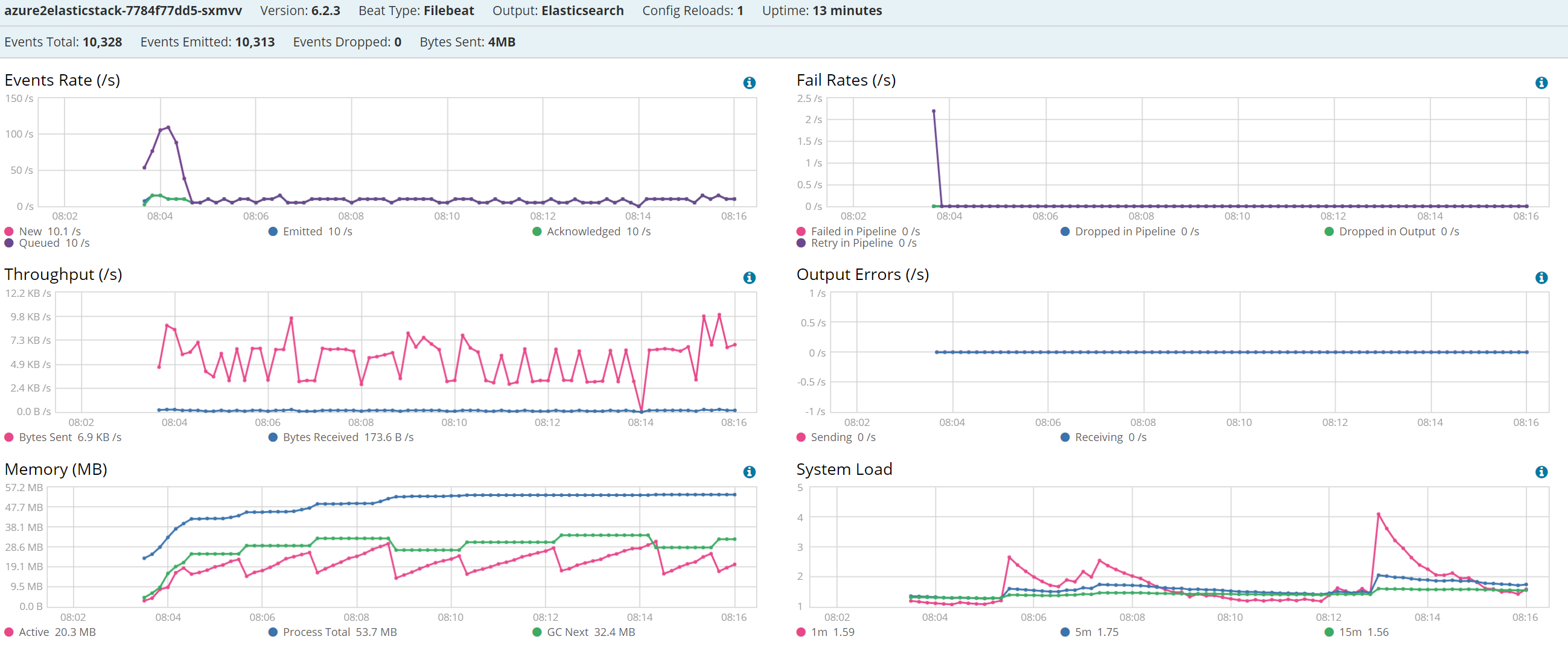
My filebeat monitoring graphs:
And my filebeat console output stats:
2018-08-03T07:13:28.751Z INFO [monitoring] log/log.go:124 Non-zero metrics in the last 30s {"monitoring": {"metrics": {"beat":{"cpu":{"system":{"ticks":300,"time":302},"total":{"ticks":1520,"time":1525,"value":1520},"user":{"ticks":1220,"time":1223}},"info":{"ephemeral_id":"4dc13585-4910-4d25-822d-94645167e2d5","uptime":{"ms":600010}},"memstats":{"gc_next":35961888,"memory_alloc":25477304,"memory_total":141147488}},"filebeat":{"events":{"active":2,"added":202,"done":200},"harvester":{"open_files":10,"running":10,"started":1}},"libbeat":{"config":{"module":{"running":0}},"output":{"events":{"acked":200,"batches":4,"total":200},"read":{"bytes":3459},"write":{"bytes":128119}},"pipeline":{"clients":1,"events":{"active":4117,"filtered":1,"published":200,"total":201},"queue":{"acked":200}}},"registrar":{"states":{"current":2,"update":200},"writes":4},"system":{"load":{"1":3.22,"15":1.6,"5":1.99,"norm":{"1":0.805,"15":0.4,"5":0.4975}}},"xpack":{"monitoring":{"pipeline":{"events":{"published":3,"total":3},"queue":{"acked":3}}}}}}}
As you can see there, it seems to be running/processing 10 files (there's one per minute). It gets way behind on events.
There doesn't seem to be any substantial load on the system at all.
Can anyone advise? Any more info I can give to help diagnose?
Bonus question: what is the "system load" stat - it's presumably not CPU core time, since the Pod in kubernetes that filebeat shares with the actual workload only peaks at ~1.13 cores?